

HTML5掌握
0
1
2
3
4
5

大家好,我是一名软件技术专业的学生。我对计算机科学和软件开发充满热情,这使我选择了这个专业。
我在这个专业的学习过程中,深入研究的编程语言有Python,C。我也学习了数据结构,算法,数据库管理,操作系统,软件工程等核心课程。这些课程不仅让我理解了软件开发的基本概念,也让我掌握了实际开发的技能。
除了课堂学习,我也积极参与各种实践项目,以提升我的编程技能和团队协作能力。我曾参与过一个团队项目,我们共同开发了一个在线购物网站。在这个过程中,我负责数据抓取。这个项目不仅让我更深入地理解了软件开发的流程,也让我学会了如何在团队中有效地沟通和协作。
我也对新技术保持关注,例如人工智能,大数据,云计算等。我相信这些新技术将对软件开发产生深远影响,我也期待在未来的学习和工作中,能够运用这些新技术来解决实际问题。
2023-10-04 -2024-04-04华夏幸福基业股份有限公司兼职
数据抓取:使用Python编写代码来模拟HTTP请求,从而从网站或API获取数据。这通常涉及到对requests库的使用,以及对网站结构和API接口的理解。 数据处理:获取到的原始数据往往需要进一步处理,如清洗、转换格式等,以便后续分析或存储。这一步骤中,可能会用到BeautifulSoup、lxml等HTML解析库,以及json、csv等数据处理库。 数据存储:将处理后的数据存储到数据库或文件中,涉及到对数据库的操作,如SQLite、MySQL、MongoDB等,或者文件I/O操作。 反爬虫机制应对:面对网站的反爬虫措施,如IP封禁、User-Agent检查、验证码等,需要有相应的应对策略,例如使用代理IP、伪装User-Agent、图像识别等技术。 自动化与定时任务:为了实现数据的定期更新,可能需要配置定时任务,如使用crontab或APScheduler等工具。
2023-09-06 - 2024-04-09江西科技职业学院软件技术专科
核心课程:数据结构与算法、计算机组成原理、操作系统、计算机网络、软件工程
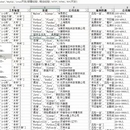
代码模拟登陆用户账号,爬取账号下的信息包括:用户基本信息、 银行卡信息、历史订单信息、物流信息、商品信息、团购信息、积 分信息等,保存 MongoDB,然后根据具体需求进行数据清洗保 存 MySQL,提供给风控后台进行风险管控,最终完成授信提供用 户相应的消费额度。 构建爬虫框架:编写爬虫基类,实现获取代理、爬取、数据保存入 库、异常处理、重爬等逻辑,不同平台继承基类实现统一调度 搭建 Django 爬虫管理平台:对各个电商网站数据爬取情况分站点展示,按照 session 对每个爬虫请求进行管理,提供测试功能通过 页面展示的登陆表单填写账号密码等信息点击登陆触发爬虫进行测试;提供查询功能查看每个 session 的爬取请求和最终爬取数据; 提供重爬功能支持页面点击手动重爬;提供统计功能可以按照日期和各种爬取状态为维度统计爬取数量和爬取成功率。 搭建 Django 验证码识别平台:对于需要验证码识别的网站,收集样本并进行标注,通过深度学习 CNN 等算法进行模型训练,然后 将训练好的模型放到 Django 项目中,提供接口给爬虫平台调用
代码模拟登陆用户账号,爬取账号下的信息包括:用户基本信息、 银行卡信息、历史订单信息、物流信息、商品信息、团购信息、积 分信息等,保存 MongoDB,然后根据具体需求进行数据清洗保 存 MySQL,提供给风控后台进行风险管控,最终完成授信提供用 户相应的消费额度。 构建爬虫框架:编写爬虫基类,实现获取代理、爬取、数据保存入 库、异常处理、重爬等逻辑,不同平台继承基类实现统一调度 搭建 Django 爬虫管理平台:对各个电商网站数据爬取情况分站点展示,按照 session 对每个爬虫请求进行管理,提供测试功能通过 页面展示的登陆表单填写账号密码等信息点击登陆触发爬虫进行测试;提供查询功能查看每个 session 的爬取请求和最终爬取数据; 提供重爬功能支持页面点击手动重爬;提供统计功能可以按照日期和各种爬取状态为维度统计爬取数量和爬取成功率。 搭建 Django 验证码识别平台:对于需要验证码识别的网站,收集样本并进行标注,通过深度学习 CNN 等算法进行模型训练,然后 将训练好的模型放到 Django 项目中,提供接口给爬虫平台调用
代码模拟登陆用户账号,爬取账号下的信息包括:用户基本信息、 银行卡信息、历史订单信息、物流信息、商品信息、团购信息、积 分信息等,保存 MongoDB,然后根据具体需求进行数据清洗保 存 MySQL,提供给风控后台进行风险管控,最终完成授信提供用 户相应的消费额度。 构建爬虫框架:编写爬虫基类,实现获取代理、爬取、数据保存入 库、异常处理、重爬等逻辑,不同平台继承基类实现统一调度 搭建 Django 爬虫管理平台:对各个电商网站数据爬取情况分站点展示,按照 session 对每个爬虫请求进行管理,提供测试功能通过 页面展示的登陆表单填写账号密码等信息点击登陆触发爬虫进行测试;提供查询功能查看每个 session 的爬取请求和最终爬取数据; 提供重爬功能支持页面点击手动重爬;提供统计功能可以按照日期和各种爬取状态为维度统计爬取数量和爬取成功率。 搭建 Django 验证码识别平台:对于需要验证码识别的网站,收集样本并进行标注,通过深度学习 CNN 等算法进行模型训练,然后 将训练好的模型放到 Django 项目中,提供接口给爬虫平台调用



