

Python精通
0
1
2
3
4
5

1、对于编程我很有耐心,有时我会卡在一个知识点好几天,但是我也会不紧不慢地去解决,这源于我对代码的热爱
2、在校期间喜欢与老师探讨各种计算机相关的问题,因为学得快因此被同学问各种问题同时也加强了人际关系
3、随着知识的不断积累,我愈发的自信,且拥有强大的的心态能够冷静地处理各种突发的问题
4、我的思维逻辑能力较强,这是因为我有深度思考的爱好,喜欢玩象棋,也很喜欢数学
5、此外,我的英语阅读能力很好,对于英语也有着深深的兴趣
项目经验:
1,获取网易云评论,运用js逆向出了post请求的表单参数,成功获取到了评论数据,分析js加密的参数值,得到cursor是获取下一页的参数,再利用递归实现了翻页机制,
2,获取酷狗音乐,先分析请求头会变化的参数,找到了signature这个未知参数,利用全局搜索找到了signature的生成过程,扣js代码利用报错信息补全了js代码并得到了这个加密参数,然后根据歌曲的songid获取到歌曲的url地址,再分析页面的url得到翻页参数‘p’利用for循环实现翻页机制,数据保存到文件夹中
3,获取知乎有关大学生社交的数据,利用drissionpage实现自动化采集,简单逻辑:url地址,监听数据包,获取响应的数据,根据需要提取出响应数据里面的信息,数据保存到mongdb
4,获取微博有关科龙空调的数据,利用playwright抓取,利用xpath提取信息,保存到txt
5,实时获取猫眼的电影数据,有字体反爬,先下载对应的字体,获取到字体的映射关系,根据字体的映射关系进行替换,利用playwright抓取数据,利用xpath提取数据,保存到xlsx文件中
6,获取实习僧关于Python的岗位信息,利用scrapy框架,先‘scrapy startproject 项目名称’新建一个项目,然后进入到setting里面关闭robots协议,添加请求头,打开管道,再到items里面明确要提取的信息,在“scrapy genspider 爬虫名称 网站域名”创建一个爬虫文件,在解析数据这里利用xpath提取数据,最后yield返回给item,最后在pipelines里面连接mongdb保存数据
2025-07-01 -2025-07-16猪八戒公司总群数据采集
目前是线上接数据采集单子,接过许多的单子,像小红书帖子的评论,微博,网易云,酷狗音乐,实习僧,淘宝这些网站都采集过,用到了js逆向,playwright自动化,drissionpage自动化,scrapy框架
2024-09-01 - 2025-07-16哈尔滨信息工程学院数据科学与大数据本科
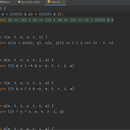
获取酷狗音乐,先分析请求头会变化的参数,找到了signature这个未知参数,利用全局搜索找到了signature的生成过程,扣js代码利用报错信息补全了js代码并得到了这个加密参数,然后根据歌曲的songid获取到歌曲的url地址,再分析页面的url得到翻页参数‘p’利用for循环实现翻页机制,数据保存到文件夹中
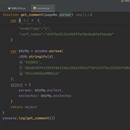
分析网页的请求方式,post请求,第一反应就是分析表单参数,表单参数有两个,一个是params,一个是encSecKey,对比多个页面,发现这两个参数是变化的,第一反应就是要用js逆向,全局搜索搜索这个不常见的encSecKey,分析encSecKey在js代码的生成过程,扣js代码,运行根据报错信息补全js代码,补全以后就在py文件中读取js代码,调用js代码获取到表单参数的加密值,根据得到的加密值发送请求,获取到获取到响应的数据,根据获取的数据进行提取,分析参数得到pageNo是页面的页数,cursor是下一页的参数,利用递归实现翻页


