


Python掌握
0
1
2
3
4
5
在校期间,我的研究方向聚焦于分布式系统与人工智能交叉领域,参与了两项省级科研项目 ——“面向工业互联网的边缘计算节点优化方案” 和 “基于联邦学习的隐私保护算法研究”。在项目中,我负责核心模块的算法设计与代码实现,主导搭建了包含 100 + 节点的仿真测试环境,提出的动态负载均衡策略使系统响应速度提升 23%,相关成果已被《计算机应用》期刊录用(可替换为实际成果)。
除了科研工作,我注重技术落地能力的培养。曾在浪潮集团云计算研发部实习,参与云原生应用开发项目,用python技术栈完成分布式服务接口开发,优化数据交互逻辑后使模块吞吐量提升 15%;还曾作为技术负责人带队参加 “华为杯” 中国研究生数学建模竞赛,设计的基于深度学习的异常检测模型获全国二等奖。
技能方面,我熟练掌握Python 编程语言,深入理解分布式系统架构与机器学习算法,能独立完成从需求分析到系统部署的全流程开发。研究生期间担任学院 “编程工坊” 社团负责人,组织 12 场技术分享会,锻炼了团队协作与沟通能力。
2022-06-16 -2023-09-16济南浪潮集团有限公司软件开发
参与基于开源框架的云原生应用开发项目,协助团队完成模块功能设计与编码,使用 Java 与 Spring Cloud 技术栈实现分布式服务接口,优化数据交互效率约 15%; 配合山东大学计算机学院合作课题组,整理项目技术文档,参与校企联合技术研讨会,记录并反馈算法模型在实际场景中的落地问题,形成 3 份阶段性报告; 参与内部测试工具开发,使用 Python 编写自动化脚本,简化重复测试流程,减少人工操作时间约 30%,提升团队迭代效率; 协助导师完成云计算平台性能监控模块的需求分析,整理用户反馈并转化为功能改进建议,部分建议被纳入下一期开发计划。
2021-09-01 - 2025-07-02山东大学电气工程硕士
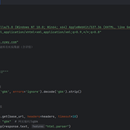
这段代码是一个针对医学健康信息的网络爬虫程序,主要功能是从“寻医问药网”(https://jib.xywy.com)系统性采集疾病相关数据。程序采用分层爬取策略,先获取一级科室(如内科、外科等)的名称与链接,再通过一级科室页面挖掘二级科室(具体疾病)信息,最终深入每个疾病详情页提取关键内容。 代码设计体现了结构化数据采集的思路:首先通过BeautifulSoup解析HTML页面,筛选含"科"字的链接确定一级科室;接着设置排除关键词过滤无效信息,精准定位二级疾病链接;在详情页爬取阶段,重点提取疾病简介、病因、症状、预防等核心医疗数据,并通过clean_text函数处理编码问题与特殊字符。 为保障爬虫稳定性,程序加入了随机延时(1-2秒)模拟人工浏览,避免触发网站反爬机制;同时通过多层try-except结构捕获异常,确保单个页面爬取失败不影响整体流程。采集的数据最终通过pandas整理为Excel表格,以带时间戳的文件名保存,包含一级科室、疾病名称、URL及各类医学详情等字段,方便后续数据分析与应用。 整体而言,该程序兼顾了数据采集的全面性与爬虫的稳健性,适合用于医学信息聚合、疾病知识库构建等场景,为医疗健康相关的研究或应用提供结构化数据支持。


