

中文母语水平
英语可口语交流
0
1
2
3
4
5
2019-06-01 -至今腾讯爬虫工程师
· 主导并维护面向内容生态的亿级日增量分布式爬虫系统,负责社交、资讯等多维度公开数据的精准采集,日均稳定处理超千万级数据请求,系统可用性达99.95%。 · 深入分析与应对复杂反爬策略,设计并实现动态渲染解析、验证码绕过及行为模拟等解决方案,将核心数据源的有效采集率提升至98%以上。 · 构建标准化数据清洗与结构化管道,利用Scrapy、Redis、Kafka等技术栈,保障数据高效流入下游推荐与风控业务,支持多部门数据分析需求。 · 主导爬虫框架核心模块重构,通过优化调度算法与引入智能熔断机制,将整体采集效率提升约40%,并显著降低运维成本。
2015-09-01 - 2019-06-01华南师范大学计算机科学与技术本科
主修计算机科学与技术,核心课程包括数据结构、算法与机器学习。期间独立开发校园信息聚合爬虫系统,实现课程与活动数据的自动化采集。曾获校级编程竞赛二等奖,并在多个数据分析项目中应用Python进行建模,具备扎实的代码与问题解决能力。
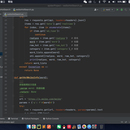
本项目核心功能包括:多维度数据采集模块、实时数据处理引擎、智能情感分析模型、社交网络分析工具及可视化交互平台。数据采集模块支持微博博文、评论、用户信息、话题榜、转发关系等数据的全面抓取,具备模拟登录、动态页面渲染及反反爬虫能力。数据处理引擎实现数据清洗、去重、结构化存储与实时更新,建立用户-博文-话
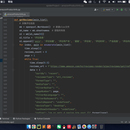
本项目核心功能包括:分布式数据爬取模块、多维度数据处理引擎、智能分析模型与可视化交互平台。数据爬取模块支持Amazon全站点商品数据抓取,涵盖价格历史、销售排名、评论情感、库存状态等20余个关键字段,具备动态渲染处理与反反爬虫策略。数据处理引擎实现多源数据清洗、归一化存储与实时更新,建立商品-商家-
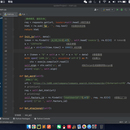
本项目主要包含四大功能模块:数据爬取模块、数据清洗与存储模块、数据分析模块以及可视化报表模块。数据爬取模块支持自动化采集1688平台商品信息,包括价格、销量、评价、商家等级等关键字段,并具备反爬应对与定时任务调度能力。数据清洗模块对原始数据进行去重、格式化与结构化处理,并存储至数据库以便后续查询。数


