

0
1
2
3
4
5
首先是做人,诚信,有责任心。
1. 掌握Scala、Python、Java语言及其技术栈;
2. 掌握大数据平台设计与架构实践;
3. 熟悉Spark、Hadoop、Hive、Kafka、Flink等常用大数据生态系统、原理及优化、核心源码;
4. 熟悉数据仓库建模,离线、实时大数据系统开发;
5. 熟悉Web后端架构与开发,了解Web前端;
6. 快速Troubleshooting能力,英语CET4:568,CET6:472。
2019-07-01 -至今某TOP数据外企大数据平台架构
基于Amazon AWS ES2、ECS、S3等基础服务搭建弹性资源、低成本的企业大数据平台。其主要功能包括:弹性基础资源申请、集群初始化(Hadoop、Spark、Hive、Livy等)、工作流创建、任务调度与管理、Web前后端研发、用户认证与安全性、日志系统等。整体设计分为平台服务端与SDK,用户通过SDK可以很容易的定义任务以及组成工作流,部署到平台服务端运行;后台服务端基于Flask框架,部署于AWS提供的Docker。该平台已上线2.0版本,支持了公司主要的数据业务流程,为公司节约机器成本50%以上。作为核心项目,后期功能增加与优化持续研发中。
2018-07-01 -2019-06-30滴滴出行高级大数据工程师
1. 滴滴运营数据项目,包括天机、POPE、Insight等,旨在为公司运营决策提供科学的数据支持,为乘客与司机提供向导。各数据产品涉及订单、司机、乘客、城市、运营活动等多个主题,支持多维度筛选、人群圈定、即席查询等,给用户展示可视化图表、漏斗数据。经过产品需求分析、按时完成了离线与实时数据开发、数仓及其表结构设计、查询引擎(Presto、ES、Druid等)选型与API、前端联调等研发工作,保障了数据产品的迭代开发效率、可用性与稳定性。使得前端页面对大数据即席查询的响应时间不超过3s。对大数据量的任务(TB、数亿级别)进行存储结构与性能优化,缩短任务执行时间,提高了自集群资源利用率。 2. 建设网约车业务统一的数据仓库,旨在支持多数据产品易用、减少重复开发、降低资源浪费。数据仓库设计分为原始表(ODS),网约车数据产品统一的数据明细层(DWD)、聚合层(DWM、DM),采用维度建模思想,关联事实表与维度表,进行指标定义,计算扩展指标,跨部门统一指标口径。该数仓目前已支持跨部门、跨产品线的业务数据需求,保障了数据易用、口径一致。得数据产品开发更加方便快捷,提高了数据易用性,节约集群计
2016-07-01 -2018-06-30百度大数据研发
基于百度云提供的基础服务建立大数据平台,实现公司业务数据计算与分析。项目内容包括:网站数据采集与传输、ETL设计与开发(适配各类非结构化数据)、数据仓库设计、任务调度系统开发(基于Azkaban)、数据报表以及元数据管理与监控等。项目已上线,稳定运行,实现了结构化与非结构化数据统一接入数据仓库,其中非结构化数据源ETL准确性高达十万分之二。为上层的数据分析提供精准稳定的数据服务,使产品、运营、编辑等基于数据做出正常决策。
2014-09-02 - 2017-06-30北京工业大学电子科学与技术硕士研究生
科研方向为物联网与大数据方向,发表多篇论文与发明专利。
2010-09-01 - 2014-06-01北京工业大学电子科学与技术本科
本科学习计算机,电子相关基础课程,参与研究生项目
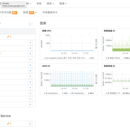
互联网+时代,很多央企,国企希望借助互联网与大数据为企业注入新的活力。该项目根据企业需求,设计与实现了大数据平台,接入了企业大部分传统数据,打破了数据之间的藩篱,使得数据更有意义,高效地支持企业决策,提高了生产效率。
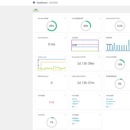
滴滴网约车涉及千万的注册司机与上亿乘客用户,千万的订单量。该系统分析与展示了整个公司的司机与乘客的各个维度的数据,支持公司运营决策,调配司乘分布,提高接单比例。
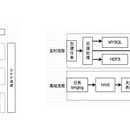
带领6名大数据工程师参与到该项目中。 已经设计与实现了以下需求: 机房: 主要包括服务器规划、网络规划、网络安全; 服务器基础运维; 大数据平台基础服务 基础存储与计算服务包括Hadoop(HDFS、Mapreduce、YARN),Hive,HBase,Spark等; 实现大数据组件 Spark、Hive 等可视化使用平台 ; 数据运维、监控、权限、安全等管理平台 ; 大数据任务调度系统; 元数据管理平台; 数据仓库建设: 根据业务数据特征进行数据仓库建模; 设计数据仓库层级,以及层级间的数据处理与流动 实现数据主题,数据集市,方便应用层进行读取与分析 数据分析: 在数据仓库支持基础数据分析; 支持自定义数据分析任务; 多任务调度,组件工作流; 承载大数据人工智能算法实施; 数据接入: 实现自动化数据采集、数据清洗、数据同步等功能; 支持数据批量导入,HTTP接口导入,手动上传; 支持用户自定义的数据源、自定义清洗逻辑等; 数据服务: 实现稳定的数据服务化、接口化; 赋能对外数据输出与共享; 数据可视化: 实现数据可视化展示; 支持自定义图表; 支持在线交互式分析; 交互式查询: 根据需求定制化OLAP查询引擎; 支持在线的,秒级响应的大数据量交互式数据查询; 支持复杂逻辑在线数据查询; 在线数据开发: 设计与实现在线数据开发服务; 支持数据仓库数据接入; 支持在线执行代码逻辑,查看结果;




