

Python精通
0
1
2
3
4
5

2018-12-01 -2020-05-01南京烽火爬虫
1:舆情类的新闻网站大部分都采集过,web端,手机端都采集过,主要就是各种新闻的数据,标题,内容,发布时间等等 2:抖音,tiktok,推特,脸书等帖子数据采集,视频数据采集 3:新闻网站的完整搭建 4:各种数据的处理,处理之后网站展示等
2013-09-01 - 2017-06-01淮南师范学院计算机科学与技术本科
作为一名经验丰富的Python工程师,我专注于利用Python技术栈构建高效、可靠的数据采集与处理系统以及完整的Web应用。我的核心能力在于实现从数据获取、处理到最终可视化展示的全链路解决方案。 在数据采集领域,我具备广泛而深入的实践经验。我熟练运用 Requests 、 Sc
1:主要模块就是抖音自动化登录,发布,利用的就是playwright来实现发布,随机选择音乐等2:内置了ai来生成文案3:利用Python来进行图片的自动合成生成图片素材4:内置了违规词进行检查文案
主要功能如下:1:各类新闻采集,通用类型的采集,可以自己增加网站2:推特帖子数据的采集定期更新3:有一个管理员管理系统,可以用来监控普通用户,更改权限等等
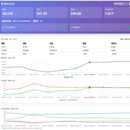
1:主要有各种网站的数据采集,包括不限于海外抖音的商品数据采集以及达人数据采集等等主要作用就是用来过滤有用的符合自己的达人数据2:视频数据采集最后利用视频数据来筛选符合自己的素材

