

0
1
2
3
4
5

1. 对新鲜技术抱有强烈的好奇心和尝试心态,喜欢自学和研究,大学期间搞过 Unreal 3 和 Unity 3D 游戏引擎、Altium Designer,Cadence PCB/FBGA、STM32 设计等。 2. 大学时开始使用阿里云服务器,主要是安装 Oracle 数据库、运行 12306 抢票脚本(尤 其年底)、Pytorch 样本集训练等;当前本地开发用 VMwareStation 虚拟机,主开发系统 使用 RHEL8.0 虚拟机(带桌面环境),本地集群为 5 个 CentOS8.0 虚拟机节点,搭建的集 群有 Redis、Mongo、ElasticSearch、Zookeeper、Kafka、Hadoop/Habase、Flink 等; 3. 工作业余时间关注比如某讯等大厂的开源发布(如 TubeMQ)等,关注 Neuroph、 AlphaGo、TensorFlow、Pytorch 等开源项目和行业技术的发展,尤其是深度学习这块, 涉及到基础数学线性代数(ML 涉及到大量的计算,个人开发买不起大规模服务器计算 集群); 4. 强迫症患者,代码没对齐看着不舒服,不太接受风格不统一和无层次结构的内容, 追求良好的代码编写风格和可读性; 5. 私认为一个不懂产品的程序猿不是好程序猿、一个只懂产品的程序猿也不是好程序 猿; 6. 有往大数据方向发展的考虑,涉及到基础数学理论和算法,认为这个比较挑战能 力; 7. 希望在企业能遇到大神级别的同事,学到更多的技术和项目经验,能够快速融到团 队中去; 8. GitHub:https://github.com/zhujiejun;
2018-10-13 -2020-12-17深圳四方精创资讯股份有限公司Java开发
1. 业务模块后端接口的开发和维护; 2. 慢 SQL 以及业务代码性能的优化; 3. 业务模块部分向微服务迁移; 4. 聊天模块集成 TIM; 5. 基于 ELK 系统性能监控平台; 6. 基于坊区动态评分和相似度的个性推荐; 7. 简单爬虫数据的获取; 8. 活跃用户、活跃坊区统计; 9. 其他新技术的引进等
2016-08-01 -2018-09-15中科软科技股份有限公司Java开发
公共:文档扫描管理功能的开发;危险单位维护功能的开发等理赔:事故代 码维护功能的开发等 再保:临分账务管理前端页面的设计及后端业务功能的开发;合约优先级前 端页面的调整及后端业务功能的开发;未决/已决分赔案查询功能前端页面的 调整及后端功能的开发;险位/事故类型的比例合约/非比例合约/临分理赔通 知中的初步出险通知书、估损调整通知书、结案通知书,比例合约/非比例合 约账户中的合约季度账、合约季度账-成数溢额混、现金赔款账、现金赔款 账-成数溢额混、预付保费账、保费调整账、超赔赔款账,临分账户中的临 分保费账单、临分赔款账单,特殊帐中的比例合约-特殊账、非比例合约-特 殊账等打印模版的设计;对接理赔的接口设计等。
2012-09-01 - 2016-06-15长江大学计算机科学与技术本科
主修课程:C/C++/C#程序设计、Java 程序设计、算法与数据结构、操作系统原理、计算 机组成原理与系统结构、数据库原理及应用、计算机网络、汇编语言与微型计算机技 术、模拟电子技术、数字电路技术、嵌入式系统设计与应用、软件工程以及每门课的实 验课程设计等
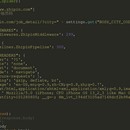
基于Scrapy爬取Boss上的岗位信息并将其存放到ElasticSearch和Excel中,通过ES的聚合计算实现各种数据分析, 最终通过Grafana图标展示
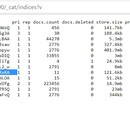
业务数据库:采用ElasticSearch作为主数据库,主要存储电影相似度矩阵和用户离线/实时推荐数据。 缓存数据库:项目采用 Redis 作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。 离线统计服务:批处理统计性业务采用 Spark Core + Spark SQL 进行实现,实现对指标类数据的统计任务。 离线推荐服务:离线推荐业务采用 Spark Core + Spark MLlib 进行实现,采用ALS 算法进行实现。 日志采集服务:通过利用 Flume-ng 对业务平台中用户对于电影的一次评分行为进行采集,实时发送到 Kafka 集群。 消息缓冲服务:项目采用 Kafka 作为流式数据的缓存组件,接受来自 Flume 的数据采集请求。并将数据推送到项目的实时推荐系统部分。 实时推荐服务:项目采用 Spark Streaming 作为实时推荐系统,通过接收 Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到ES数据库。
乐寻坊是以人才为中心,基于区块链技术和通证经济激励体系,为人才用户 提供求职、培训、活动以及人才群体之间的交流互助等全方位服务的人才互 动平台。 乐寻坊致力于构建企业、培训机构、行业协会、院校、监管机构等 多方参与的联盟链,通过联盟链成员开发的各类蜂巢应用,全面链接人才服 务。



