

0
1
2
3
4
5
我是程序员客栈的寇先森一直在进步,一名后端(Java)和大数据研发工程师; 我毕业于大连理工大学,担任过易车公司的大数据研发工程师,担任过玩吧公司的资深大数据研发工程师; 负责过易车大数据平台研发和构建及信息流推荐系统的研发,玩吧埋点平台和玩吧用户行为分析平台的研发,玩吧广告管理平台和广告数仓的开发; 熟练使用Java,SpringBoot,mybatis,mysql,redis,hadoop, Flink 以及Linux操作系统 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2020-04-01 -至今玩吧资深大数据研发工程师
项目一:玩吧埋点管理平台 + 用户行为数据分析平台 + 玩吧实时数仓 技术栈:Flink + Kafka/SLS + Hologres + Maxcompute 项目描述: 玩吧用户行为日志收集和分析系统原来使用的神策数据提供服务,没有自己的离线数仓和实时数仓。但是在业务发展越来越多样化和用户量越来越大的背景之下,神策数据已经满足不了目前的数据需求。为了替换掉神策同时建设自己的离线和实时数仓,数据智能团队开始了玩吧自有埋点系统和实时数仓的建设。 个人项目职责: 本人在该项目中负责整个项目的工程架构设计、技术选型和核心模块开发,协调各端开发和测试的工作,推动整个项目在业务侧的落地。 1.玩吧埋点管理平台建设 玩吧埋点管理平台建设主要分为四部分:埋点SDK研发、埋点模型设计、埋点规范制定和埋点元数据管理。 考虑到项目开发效率和技术成熟度以及业务侧埋点的成本,项目采用了神策开源的SDK作为埋点上报SDK,同时做到了全公司各业务各端SDK统一化和标准化,制定了埋点端到端采集的规范,设计出灵活、全面、复用性高的埋点模型。在埋点规范统一的基础上开发出埋点元数据管理,实现了埋点的上下线管理、事件
2019-06-16 -2020-03-31小猪短租高级大数据研发工程师
项目一:小猪实时数据计算平台 技术栈:Flink +kafka +hadoop +Redis +mysql 项目描述: 小猪短租日志采集系统搭建完成之后,公司所有实时数据包括日志数据、binlog 数据、mq 数据及监控数据均汇聚 kafka, Flink 作为分布式流数据计算引擎对公司推荐排序、个性化搜索、营销召回等实时业务进行数据支持 个人项目职责: 1.实时数据准备,做到口径统一 公司原有流数据来源多而杂,Flink 消费时业务划分困难而且非常容易造成 checkpoint 超时;为解决这个难题,将用户行为日志数据和中台业务 mq 数据统一发送到 kafka 集群,mysql binlog 数据利用 canal 发送到 kafka 集群,实时数据源统一为 kafka。 2.Flink 实时计算 利用 Flink on Yarn 进行实时流计算开发,职责从前期工程架构设计到后期代码重构以及所有实时项目的调优及运维监控; 业务支撑包括:用户聊天实时风控系统,根据用户行为实时推荐靠谱用户给房东,房态实时更新,智能营销召回系统,个性化搜索特征实时计算更新以及房源分实时计算更新,新房源智
2018-02-26 -2019-06-15易车大数据研发工程师
项目一:易车大数据实时数据分析平台 技术栈:kafka +Impala +kudu +CBoard+elasticsearch+logstash+kibana 项目背景: 前期数据采集系统搭建完成之后,因为离线数仓只能提供 n-1 天的数据报表,因此对实时数据分析统计平台需求迫在眉睫。 项目描述: 实时数据分析平台分为两部分: 1.开发一套作为神策数据替代品的系统可以满足在 web 上轻松实现对用户行为埋点不同维度上的实时数据分析。 2.开发一套可以实时看到当日 PV,UV,DAU 及活跃搜索词汇及活跃用户地理位置并支持定期更新的数据大屏系统。 个人项目职责: 1.实时数据分析系统 消费 kafka 数据,使用 Kudu 作为存储系统,使用 impala 作为 SQL 分析引擎,对开源 BI 工具二次开发用于接入 impala 实现对埋点数据的可视化分析操作,对数据可视化系统进行性能调优,包括 tomcat 调优和 GC 调优。 2.实时数据大屏系统 独立搭建 ELK 集群,对 ELK 集群进行性能调优;使用 logstash 消费 kafka,进行一系列转化后接入 elastics
2014-07-01 -2018-02-15东软集团Java研发工程师
由于大学本科不是计算机专业,毕业的时候以Java研发实习生的身份进入东软,毕业之后留在了东软。在东软期间参与研发了大连东软医疗信息采集平台的研发、东软财务信息平台研发和其他项目。
2010-09-04 - 2014-06-24大连理工大学港口航道与海岸工程本科
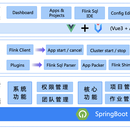
实时计算平台 规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的Connectors,标准化了配置、开发、测试、部署、监控、运维的整个过程, 提供了scala和java两套api, 其最终目的是打造一个一站式大数据平台,流批一体,湖仓一体的解决方案 功能如下: Features 开发脚手架 多版本Flink支持(1.11、1.12、1.13、1.14、1.15) 一系列开箱即用的connectors 支持项目编译功能(maven 编译) 在线参数配置 支持Application 模式, Yarn-Per-Job模式启动 快捷的日常操作(任务启动、停止、savepoint以及从savepoint恢复) 支持火焰图 支持notebook(在线任务开发) 项目配置和依赖版本化管理 支持任务备份、回滚(配置回滚) 在线管理依赖(maven pom)和自定义jar 自定义udf、连接器等支持 Flink SQL WebIDE 支持catalog、hive 任务运行失败发送告警邮件(支持钉钉、*、邮件、飞书等) 支持失败重启重试 从任务开发阶段到部署管理全链路支持
广告投放主要为各种信息流渠道和应用商店渠道,之前使用第三方平台对投放广告进行监测和用户归因。但是面临着很多问题,比如归因准确性,数据安全和投放数据回收应用等问题,针对以上问题开发了自己的信息流广告管理平台。 个人项目职责: 本人在该项目中主要负责广告监测服务开发、信息流广告数据对接服务开发等,协调项目各个开发人员的工作,推动整个项目在业务侧的落地。 1.广告监测服务+广告数仓 目前主流的信息流广告商都提供了广告监测链接模板,使用该模板生成针对性的广告监测链接,广告监测链接的属性信息会带有渠道ID、广告ID、用户设备MEI、用户设备指纹等信息。广告曝光和被用户点击时就会对广告监测服务发生请求。该服务使用SpringBoot开发,后端收到用户请求之后会对将请求数据发给kafka。kafka的数据会对接Maxcompute做离线归因和Flink进行实时归因。 2.信息流广告数据对接服务 用户激活和注册数据也写入kafka,Flink实时消费用户激活和注册数据之后进行实时归因,归因平台拿到两方数据后,通过数据分析,将广告平台的数据跟用户行为联系起来,最终将归因匹配的结果上报给广告商。
用户行为日志收集和分析系统原来使用的神策数据提供服务,没有自己的离线数仓和实时数仓。但是在业务发展越来越多样化和用户量越来越大的背景之下,神策数据已经满足不了目前的数据需求。为了替换掉神策同时建设自己的离线和实时数仓,数据智能团队开始了自有埋点系统和实时数仓的建设。 本人在该项目中负责整个项目的工程架构设计、技术选型和核心模块开发,协调各端开发和测试的工作,推动整个项目在业务侧的落地。 1.埋点管理平台建设 埋点管理平台建设主要分为四部分:埋点SDK研发、埋点模型设计、埋点规范制定和埋点元数据管理。 考虑到项目开发效率和技术成熟度以及业务侧埋点的成本,项目采用了神策开源的SDK作为埋点上报SDK,同时做到了全公司各业务各端SDK统一化和标准化,制定了埋点端到端采集的规范,设计出灵活、全面、复用性高的埋点模型。在埋点规范统一的基础上开发出埋点元数据管理,实现了埋点的上下线管理、事件属性管理、埋点实时数据校验等功能,方便业务方使用和管理埋点。 2.埋点日志收集及在线分析系统建设 埋点日志收集及在线分析系统分为三部分:埋点日志收集技术架构设计、埋点日志实时ETL技术选型、OLAP组件选型。 针对需求分别设计了开源组件架构和云原生组件架构两种架构方案,在技术完整性、项目成本、项目可维护性等考虑之下最终选择了云原生组件架构。该项目使用阿里云日志服务(SLS)作为日志接收、传输和日志总线组件,使用Flink进行用户埋点ID-MAPPING和埋点日志实时ETL,使用分析型数据库Hologres作为埋点日志存储和OLAP分析组件。 3.实时数仓建设 实时数仓选用SLS+Flink+Hologres的架构。数据模型分三层,ODS(DWD)->DWS->ADS。ODS(DWD)层明细数据存储在SLS中,DWS层数据使用Hologres列存表存储,按照主题整合,构建可复用的DWS层,减少烟囱化。由于Hologres同时支持行存和列存,ADS层指标数据直接输出Hologres行存表对外提供服务。
