

0
1
2
3
4
5

2019-09-13 -2023-03-06山西传世科技有限公司大数据开发工程师
负责Spark、Flink、Hive、SQL编码;参与会议制定需求;对接后端人员指定数据格式;协助测试人员和前端人员测试接口。
2015-09-01 - 2019-07-01山西工商学院计算机科学与技术本科
## 互联网广告(开始时间不详,止于2020.11) ### 概述 运用大数据技术细分用户喜恶,再根据用户喜恶权重投放广告,从而大幅提升了广告的转化率。 ### 实现 数据采集: - 使用Flume从各日志服务器采集埋点日志到Kafka。 - 使用Sqoop从MySQL导入数据到HDFS。 数据处理: - 实时 - 使用SparkStreaming实时处理来自Kafka的数据并保存结果到Redis。 - 离线(先用Flume从Kafka采集数据到ODS层,此步骤起到一个备份的作用。再用Spark清洗数据到DWD层,用于离线处理的统一入口) - 使用Hive分层搭建数仓并保存结果到MySQL。 - 使用Spark对用户打标签并保存结果到HBase。 - 使用推荐算法分析数据并保存结果到MySQL。 数据展示:使用ECharts展示数据。 ### 个人职责 搭建Flume集群。 参与Spark离线编码(含ETL)。 使用Hive离线编码。 打标签以生成用户定向。 对接后端人员。 协助测试人员。 参与会议。 杂项任务:校验数据。
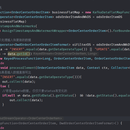
### 概述 运用互联网、大数据、AI技术(尚未引入,我离职时正在招聘机器学习工程师)构建信息化的物流平台,连接物流、仓库、人、车、物等所有管理对象,从而降低运营成本。 ### 实现 数据处理: - 实时 - 根据“数据操作类型”清洗数据并保存到Redis。 - 异步关联维度表以生成宽表并保存到Kafka。 - 风控:生成风控数据并保存到redis。 - 大屏:生成大屏数据并保存到mysql。 - 使用flinksql三流join并保存到mysql。 - 离线 - 使用sqoop编写shell脚本从mysql导入数据到hive。 - 一层表沉淀。 - 二层表沉淀。 - 指标计算。 - 离线指标计算。 - 风控。 数据展示:先用MyBatis映射Java接口和数据库,再用SpringMVC接口生成JSON数据。 ### 个人职责 参与Flink实时编码。 参与Hive和MySQL离线编码。 参与Sqoop脚本编写。 协助前端人员测试数据接口。 对接数据分析师。 对接产品经理。 对接后端人员。 协助测试人员。 参与会议。 杂项任务:迁移数据库、校验数据。

