

中文母语水平
0
1
2
3
4
5
2023-01-01 -至今Google爬虫
项目一:【大型电商评论数据采集系统】 • 角色: 独立开发 • 描述: 针对某头部电商平台,设计并实现了高并发分布式爬虫系统。解决了动态 JS 加密、滑块验证码及 IP 封禁问题。 • 成果: 日均采集评论数据 50W+ 条,稳定运行 6 个月以上,数据准确率达 99%。 • 技术栈: Python + Scrapy-Redis + Redis + MySQL + Proxy Pool 项目二:【招聘信息聚合与分析工具】 • 角色: 独立开发 • 描述: 抓取主流招聘平台的岗位信息,进行关键词清洗与薪资分析。 • 成果: 帮助客户快速生成行业分析报告,支持导出多格式 Excel 文件。 • 技术栈: Python + Selenium + Pandas 项目三:【社交媒体舆情监控爬虫】 • 角色: 核心开发 • 描述: 定制化抓取特定关键词的舆情数据,支持实时监控与增量更新。 • 成果: 完成 10+ 站点的适配,支持动态翻页与反爬策略。
2015-07-01 - 2019-07-01电子科技大学爬虫本科
核心课程与主修 • 计算机基础: 数据结构与算法、计算机网络、操作系统、数据库原理 • 软件开发: Python 编程、Web 前端开发 (HTML/CSS/JS)、软件工程 • 数据科学: 数据库设计、数据挖掘与分析、机器学习基础
作品三:招聘信息聚合与分析小助手?核心能力:爬虫定时任务、数据可视化、批量导出•项目描述:一个自用的聚合工具,定期抓取主流招聘网站上的特定岗位数据,用于分析行业薪资水平与技能需求。•技术亮点:◦设计定时任务(Crontab),实现每日自动增量抓取。◦使用Pandas进行数据清洗与分析,自动剔除重复与
作品二:动态网页数据提取工具?核心能力:JS逆向、Playwright自动化、数据API封装•项目描述:针对某资讯/博客类网站,该网站采用前端框架渲染数据,常规请求无法直接获取内容。•技术亮点:◦采用Playwright进行浏览器自动化模拟,解决动态JS渲染难题。◦分析接口加密参数,通过Python
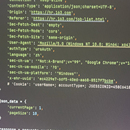
作品一:多线程电商评论爬虫?核心能力:通用爬虫架构、数据清洗、并发处理•项目描述:针对某主流电商平台,开发的批量抓取商品评论与评分数据的工具。旨在帮助运营人员快速收集市场反馈进行竞品分析。•技术亮点:◦使用Python+Aiohttp实现异步高并发请求,大幅提升抓取效率。◦内置自动反爬机制,包括代理



