


中文母语水平
0
1
2
3
4
5

1能够根据业务需求深入研究并制定高效的爬虫策略,独立设计并开发分布式爬虫系统,支持高并发、多平台的数据抓取,显著
提升数据采集效率与稳定性。
2. 负责网页信息的提取与清洗工作,完成数据结构化处理与入库流程开发,确保数据质量与完整性,为后续数据分析提供可靠的
数据基础。
3. 熟悉常见反爬虫机制,具备应对Cookie验证、JS加密、Base64编码等反爬技术的实战经验,有效提升爬虫的鲁棒性与抓取成
功率。
4. 熟练掌握HTML解析技术,能够灵活运用正则表达式、XPath等工具进行数据提取,提升数据采集的准确性与效率。
5. 熟练使用AI编程辅助工具,提升代码编写效率与质量,优化开发流程并缩短项目交付周期。
6. 熟悉MySQL等常见关系型数据库,具备数据存储与查询的开发能力,支持高效的数据管理与分析。
7. 了解动态网页抓取及浏览器自动化技术,具备使用相关工具实现复杂网页数据采集的能力,扩展了数据获取的广度与深度
2025-04-10 -2026-04-01拓尔思集团总部助理爬虫开发工程师
借助AI工具辅助开发Python爬虫脚本,完成静态/动态网页的定向数据采集与解析 针对网页反爬机制优化采集策略,保障数据抓取的稳定性与合规性 对抓取的原始数据进行清洗、去重、结构化处理,输出标准化业务数据 维护爬虫脚本运行,排查采集异常、网页适配等问题,确保任务高效执行 配合团队对接数据需求,整理爬虫开发文档与采集规范
2021-09-01 - 2025-06-20哈尔滨金融学院软件工程本科
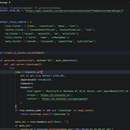
该项目是一个针对m.itouchtv.cn网站的爬虫工具,通过模拟浏览器请求、生成HMAC签名和动态构造请求头,绕过网站反爬机制,从API接口获取新闻列表和视频内容,并解析出标题、时间、链接等关键信息,最终生成可直接访问的文章链接或m3u8视频播放地址。


