

0
1
2
3
4
5

2018-01-01 -至今上海启赟金融有限公司Java开发工程
主要从事供应链金融相关业务开发,包括收款,收单,贷款等业务。主要涉及技术栈有spring,mybatis,dubbo,springboot,springcliud alibaba等等
2017-01-01 -2018-01-01武汉金力有限公司后端开发工程师
主要负责供应链相关业务开发,负责日常业务需求迭代,以及相关bug修复。主要涉及技术栈有spring,soringmvc,mybatis等框架。
2013-09-01 - 2017-07-01武汉大学珞珈学院软件工程本科
本科学历
该系统为人力资源管理平台,用人单位发布需求,人力资源单位招募员工,平台负责分发消息,以及统计考勤,计算返费,奖金等。本系统使用springcloud alibaba相关技术,接入了链路追踪,oauth2认证,服务降级等相关技术,支持分布式部署,支持docker部署
本项目为个人作品,模仿*的即时通讯APP,主要结构为三个fragment,使用自定义组件,自定义动画,缓存等android相关技术,使用xmpp做为通信协议,支持消息推送,朋友圈等功能
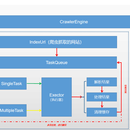
1.CrawlerEngine 这个类是爬虫引擎的抽象类,定义了爬虫引擎的加载,启动,暂停,重启,停止等操作。 Crawler 是一个核心爬虫工作单元,定义了爬虫的地址,爬虫的类型,爬虫任务列表等一些信息。 Task 是爬虫任务执行单元。一个爬虫引擎可以部署多个爬虫单元,一个爬虫单元会有N多个爬虫任务执行。 2.爬虫执行任务单元分为 SingleTask (单页任务)和 MultipleTask (多页任务),由于数据量巨大,在设计系统的时候会采用分页展示的手段,分页分数就是为了针对这种情况而设计的。 3.当爬虫引擎部署好爬虫并且开始启动执行,那么首先会从爬虫单元(Crawler)中取出爬虫的目标地址等相关信息创建一个启动的Task,然后将Task放入TaskExecutor中执行,执行完成之后对执行结果进行解析-》处理解析结果-》清理数据缓存,到此处这个Task执行完毕,然后再从爬虫单元中取出下一个Task进行任务分发。具体的详细过程大家可以参考源代码自己研究。


