


0
1
2
3
4
5
2016-07-13 -至今中旭昊智能科技发展股份有限公司高级后端工程师
1.负责大数据平台架构,部署 2.负责项目大数据部分代码编写 3.负责部分前端系统编写 4.负责服务器运维 5.负责部分网络安全
2017-07-01 - 2018-12-01北京联合大学商务管理专科
这个是我在上班时间考的自考学历,成功接触并学习了会计,金融,财务,人力等相关知识
2011-09-01 - 2015-07-01北京信息工程专修学院计算机科学与技术本科
1.在校期间获得高级软件工程师证书
该系统采集了微博、*、论坛、贴吧、新闻网站等网络媒体的文字信息,定制了数据清洗、存储、分析、检索、呈现等服务,以图表、文字等形式向用户呈现了粮食行业新闻、粮食价格走势、粮食信息监测等内容,为粮食生产、收购、储备提供了可靠的决策支持。
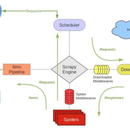
1.因为爬取的网址量比较大,所以普通的单个爬虫无法支持项目,所以选择基于scrapy-redis的分布式爬虫 2.爬虫的爬取结果通过kafka直接保存在ES中 3,爬虫的结果可以通过kibana直接查看
该程序利用*公众号提供的API,实现了在*公众号官方平台未提供的功能,实现了*公众号与后台交互数据的本地化存储,解决了*公众号存储数据依赖腾讯后台的问题,方便用户管理使用自己的数据,分析用户数据,来做更好的推广