

0
1
2
3
4
5

2019-03-01 -至今字节跳动大数据工程师
在字节跳动从事大数据开发,后端开发工作。使用技术栈:golang,flink,haoop生态,elasticsearch 等
2017-03-01 -2019-03-01美团点评大数据工程师
大数据工程师,负责美团配送智能调度系统实时数据体系建设,为智能调度算法题实时特征。技术栈:java storm elasticsearch等
2013-07-01 -2017-03-01搜狐大数据工程师
从事社交产品大数据开发工作,负责报表系统设计和开发,以及日常需求的跟进,技术栈:java spark streaming kafka等
2009-09-01 - 2013-06-01华中科技大学电子信息工程本科
华科电信系本科
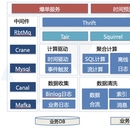
项⽬目简介:同步多个业务库binlog,⽤用storm清洗、join出宽表落⼊入缓存,⽤用分布式服务在 宽表上计算特征并落⼊入缓存,⽤用服务化对外提供特征查询 项⽬目细节:使⽤用databus同步业务库binlog或者使⽤用⽇日志中⼼心组件收集业务⽇日志,将数据 打到kafka,⽤用storm完成数据清洗、多流合并、建⽴立索引,将合流的宽表数据落地到缓 存,下游使⽤用服务每分钟通过索引拉取缓存中关注的数据(并清理理过期数据),在内存数 据库H2中进⾏行行SQL运算,⽣生产各种维度的的指标并落地到缓存集群,供特征查询服务使 ⽤用。各个环节可以通过元数据管理理系统进⾏行行扩展,⽐比如统计指标⽤用的SQL,⽐比如合流的添 加。整个系统对外提供约300个特征,⾼高峰期特征查询QPS达到50w,提供了了配送智能调 度系统所有算法使⽤用的实时特征数据
收集业务⽇日志到MQ,⽤用spark-streaming完成清洗得到明细数据并落地到 hive,⽤用定时etl计算⼩小时级指标,指标存⼊入hbase,供bi系统展示。 项⽬目细节:使⽤用flume收集业务服务的⽤用户⾏行行为⽇日志,将数据打到kafka,下游使⽤用spark- streaming将数据清洗成明细数据表落地到hive,使⽤用定时任务每⼩小时调度spark统计程 序,统计上⼀一⼩小时的⽤用户⾏行行为指标(pv,uv,⽤用户评论数等),数据落地到hbase,供BI 做报表展示使⽤
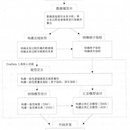
项⽬目简介:对实施数据进⾏行行分层建设,分成ODS、DWD、DIM、DWS4层,DWS层数据 按需落到存储,存储之上构建统⼀一查询引擎,对外提供统⼀一接⼝口,让下游查询指标 项⽬目细节:系统由one data和one service两部分组成。one data对实时数据进⾏行行分层建 设,分成ODS、DWD、DWS、DIM四层,ODS的数据直接采集业务库binlog或者业务的 app log,通过flink引擎清洗,过滤,合流,join DIM数据等操作⽣生成宽表之后,就是 DWD层的数据,下游再使⽤用flinkSQL计算,统计出指标,落地到存储即是DWS层数据。 每层可以通过管理理端配置实现扩展,层和层以kafka为中转。one service构建是DWS层之 上的数据查询服务,通过在apache calcite上进⾏行行⼆二次开发,屏蔽了了各种存储引擎,提供 统⼀一的逻辑视图,⽤用户在逻辑视图上配置查询的SQL,通过接⼝口获取SQL对应的数据。



