

0
1
2
3
4
5

我是程序员客栈的竹林子07,一名全栈开发开发人员;拥有自己的平台作品2部,代码生成平台和爬虫平台
19-22在软通动力给华为和荣耀做数据集成系统
Java基础方面:
熟练使用集合,多线程,线程池,常用的设计模式,gc工具,对jvm原理及数据结构与算法有一定的了解。对高并发及锁有着比较深入的理解。
Javaee框架方面以及源码:
熟练使用SpringCloud、Spring、SpringBoot、Mybatis的TK插件、MyBatis-Plus,对Spring、SpringBoot、Datax、RocketMq源码的核心流程有一定的了解。
中间件框架及大数据方面:
熟练使用Kafka、RocketMQ以及Redis、ES中间件。
熟悉hadoop环境(hdfs,hive,hbase),对hive有着深入了解。
数据库方面:
能熟练使用MySQL、Mongodb、Oracle、PostgreSQL、GaussDB数据库进行开发,深入了解sql性能优化及数据库事务。
前端方面:
能在项目中熟练使用vue,elementUI,es6语法。
开发工具方面:
熟悉使用IDEA, Eclipse, Git,Navicat,Postman,IDEA常用的插件,Mat
服务器方面:
熟练使用centos的服务器,阿里云服务器,shell命令脚本,配置tomcat以用Docker部署服务器,熟悉使用常用的k8s及docker命令,独立部署kafka,rocketmq,es,redis集群以及elk。
2019-10-15 -2022-09-20软通动力java高级开发工程师
华为和荣耀的数据集成系统,主要将各种数据的类型的实时或者定时进行数据转换,数据类型包括mysql,oracle等关系型数据库,以及kafka和mqs中间件,及obs及ftp文件类型,fihive和hdfs和fibase大数据类型。
2017-04-12 -2019-08-14巨灵信息有限公司java中级开发工程师
编写爬取工具,负责财经类型信息的抓取,前端C#, 后端java,爬取,解析,入库和任务监控的逻辑的开发
2009-09-01 - 2013-07-01云南财经大学工商管理本科
项目名称:快速数据集成系统 项目描述: 主要将各种数据的类型的实时或者定时进行数据转换,数据类型包括mysql,oracle等关系型数据库,以及kafka和mqs中间件,及obs及ftp文件类型,fihive和hdfs和fibase大数据类型。用分布式系统,前端react主要是数据源及任务配置,adapter任务分化,各种类型插件的reader读完之后,数据缓存在中间件kafka和mqs,再从中间件把数据拿出来,writer插件写入到目标库里面,monitor参与进行插件服务器的监控。上面的是数据分发模式,还要点对点fdiworker模式,读写在一个服务器上面,通过内存做中间件缓存。我这边主要负责fihive插件,将fihive读写性能最优化以及解决客户问题及新的需求,后置处理器的保持数据的不丢失及数据能及时到客户的api接口或者指定的mqs的topic中。adapter收集所有的任务的执行状态,收集用elk链路日志,方便追踪任务问题。Fdiworker使用的内存是有限的,使用容易出现内存溢出,需要排查与修复。红区部分的网络和绿区不通,需要整改部分代码逻辑才能使用,红区的所有的fdi的代码都要负责。公共核心包common编写及维护,后期参与到项目的安全版本升级及代码安全整改。 责任描述: 1.绿区的fihive读写普通插件及Fdiworker的fihive插件以及后置处理器 2.红区的整个fdi
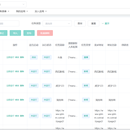
项目目的:通过页面轻量配置,抓取互联网网站数据。支持自定义代理IP抓取,将请求分发给多个代理IP进行爬取,支持自定义缓存和入库数据源,用户根据自己的需求选择最终入库的数据源,同时所有的爬取的缓存数据也会直接给用户,支持url排重,定时爬取,支持批量更新入库的数据,支持Chrome浏览器驱动爬取网站。 作品地址:http://1.15.140.221/#/home 1、主要模块:租户应用、数据源、IP代理、任务、模板的导入导出 租户应用 :用户可以拥有独自的应用,与他人共享应用(与他人合作),以及将自己的爬虫任务发布公共应用(其他应用获取) 数据源:数据源是用户租户可以共享的,任务爬取的数据(缓存和入库数据),用户自己选择将这些需要落地的数据入哪个数据库 IP代理:自定义代理IP配置(反反爬虫策略动态IP配置) 任务配置:①任务的基本设置 任务基础属性配置(任务名称、类型) ②公共设置 编码、cookie(需要登录)、是否使用虚拟浏览器、是否使用自定义代理IP、是否使用缓存数据库、是否手动设置排重 ③获取分页地址(首个地址)支持表达式配置,将生成批量url地址 ④获取内容页面地址 通过首个地址发送请求(支持GET、POST请求)获得页面源码,通过XPath选区,正则表达式提取url链接,如果这个url只是 分级页面,再循环上面的方法,最终提取需要的内容页面url ⑤解析数据(内容页面):选择入库的字段,通过工具(XPATH,正则表达式、jsoup...)通过内容页面提取内容 ⑥获取爬取解析数据:抓取解析部分层级数据做测试,看看配置是否出错 ⑦入库:入库的数据源配置,爬取解析数据有数据的时候,可以点击入库,看看数据能否正常的入库 ⑧调度:配置调度时间 任务的导入导出:任务模板导入导出给给其他的租户使用,没有必要重新编写任务 技术:前端vue-element-admin,后端 nacos、gateway、springCloud、webmagic、quarter、selenium
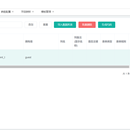
项目目的:减少开发者的开发量,代码生成整个过程还是比较繁杂的,用户只需要关注平台封装数据和编写自己需要代码模板,其他的都由平台完成。 作品地址:http://120.25.157.37/generator/#/home 1、主要模块:租户应用、数据源、代码生成、模板的导入导出 租户应用 :用户可以拥有独自的应用,与他人共享应用(与他人合作),以及将自己的模板发布公共应用(其他应用获取) 数据源:用户独立的部分,可以选择数据源的表,对字段进行标识 代码生成:①参数配置 基础属性配置(生成文件的名称、路径、作者,自定义值) ②字段映射 表字段映射需要的类型 ③模块名称 生成代码的模板 ④生成代码 数据源选择表,编写表字段,选择代码生成按钮,选择组,生成代码 模板的导入导出:生成代码的模板导入导出给给其他的租户使用,没有必要重新编写 技术:前端vue-element-admin,后端 nacos、gateway、springCloud

