

中文母语水平
英语专业级流畅
0
1
2
3
4
5

2023-06-07 -2026-04-24华为软件开发
• AI 与算法开发: 专注于 LLM 应用层开发。擅长构建基于 RAG(检索增强生成) 的多智能体系统(如 LogPilot),熟练使用 Ollama、vLLM 进行模型部署,以及 Cursor 辅助高效编程。 • 无线通信与同步: 拥有华为无线平台开发经验,精通 PTP (I
2020-09-01 - 电子科技大学自动化硕士
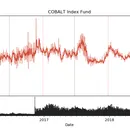
使用Python进行Steam数据爬取是一个非常有趣和有用的项目。Steam是一个游戏平台,拥有大量的游戏和用户数据。通过爬取Steam数据,可以获得有关游戏、用户、评论等方面的信息,从而进行分析和挖掘。 在项目中,使用了Python的一些库和工具,如BeautifulSoup、Requests、Selenium等。这些工具可以帮助从Steam网站上获取所需的数据。可以使用Requests库向Steam服务器发送HTTP请求,然后使用BeautifulSoup或Selenium解析响应内容。您可以使用这些工具来获取游戏列表、游戏详情、用户信息、评论等数据。

用 python 对淘宝数据进行爬取的项目非常有意思。以下是对这个项目的简单介绍: 这个项目的目的是通过 Python 爬虫技术获取淘宝网站上的商品信息,并对数据进行分析和处理。主要分为以下几个步骤: 确定爬取的目标:选择需要爬取的商品类别和关键词,确定需要获取的商品信息,如商品名称、价格、销量、评价等。 编写爬虫程序:使用 Python 的 requests 和 Beautiful Soup 等库进行网页数据的请求和解析,获取需要的商品信息。 数据清洗和处理:对获取的数据进行清洗和处理,去除重复数据、异常数据和无用信息,使数据更加准确和可靠。 数据分析和可视化:使用 Python 的 pandas、numpy 和 matplotlib 等库对数据进行分析和可视化,得出有意义的结论和图表。 结果展示:将分析结果呈现给用户,可以选择将结果保存为 Excel 表格、图表或者网页展示等形式。 这个项目可以帮助用户了解淘宝网站上的商品信息,对于商家可以了解市场情况,对于消费者可以选择更加合适的商品,同时也可以提高用户对 Python 爬虫技术的认识和应用能力。
实现了chatgpt的网站部署,采用flask框架将其部署在了vps上。ChatGPT是一个强大的自然语言处理模型,可以用来生成自然语言文本,如对话、文章、摘要等。将其部署在VPS上,可以让访问者通过网站与ChatGPT进行交互,从而获得自然语言生成的结果。 在部署ChatGPT时,我选择了Flask框架,这是一个轻量级的Web框架,适用于小型Web应用程序。Flask具有简单易用的API,可以快速构建Web应用程序。我可以使用Flask来处理HTTP请求和响应,并将ChatGPT的生成结果返回给用户。 在我的ChatGPT网站上,提供了一个文本框,让用户输入文本,然后将该文本发送到服务器上的Flask应用程序。Flask应用程序将文本发送给ChatGPT模型进行处理,并将生成的自然语言文本返回给用户。还可以添加其他功能,如历史记录、用户身份验证等,以提高用户体验。 总的来说,ChatGPT网站的部署是一个非常有趣和有用的项目。


