

0
1
2
3
4
5

2022-11-01 -至今西南大学签约公司学生
主要负责数据爬取,对爬取的数据通过正则表达式,爬取文本内容中想要的数据,进行筛选,偶尔也可以写一点前端,写一些好看的页面
2021-09-01 - 西南大学软件工程本科
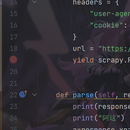
在数据进行爬取的时候遇到了很多问题,在使用scrapy框架时需要下载很多python的库,比如scrapy,然后还需要重新调制scarpy当中的参数,比如BOT_NAME = "boss" SPIDER_MODULES = ["boss.spiders"] NEWSPIDER_MODULE = "boss.spiders" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"在此框架下既可以使用selenium也可以使用requess也可以二者结合
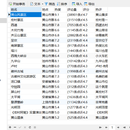
这两个网站我用的request即可,因为在对页面进行分析的时候,发现很轻松的就找到了隐藏的js文件,阿贾克斯文件,获取url后,再去获取相关的data或者parms参数,两个网站都需要在登录的情况下进行数据的爬取,所以就需要保留当前页面的cookie,全部都加载头文件中,headers,这样即可访问隐藏的数据,再将数据存到mysql当Z中,实现永久存储
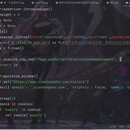
使用了selenium,因为小红书的反爬机制很强,所以填了一个stain.js的文件避免被封掉ip 成功登录以后即可为心所欲,在页面爬取时,因为页面的数据是动态加载的,所以我们还需要一些js的操作,每隔5秒自动向下滑动滑轮一定距离,是的数据远远不断的刷新,判断当前页面是否到底,只需要判断当前页面的高度是否有改变,如果一直没变,则说明数据爬取完毕,任务结束


