


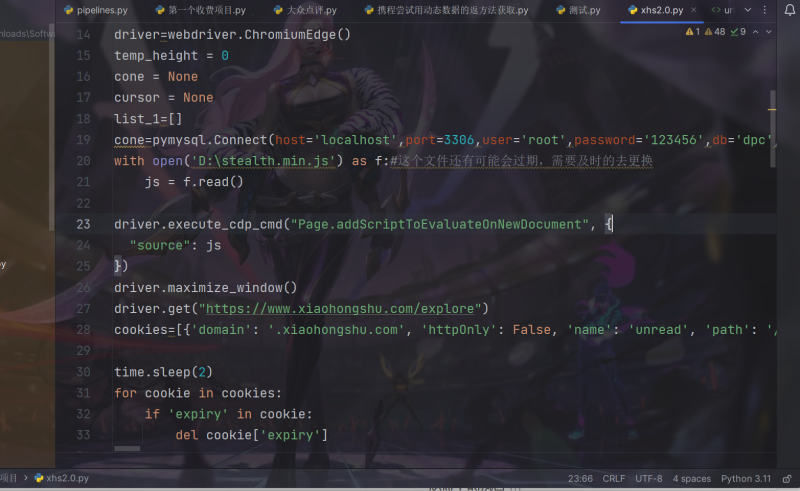
使用了selenium,因为小红书的反爬机制很强,所以填了一个stain.js的文件避免被封掉ip
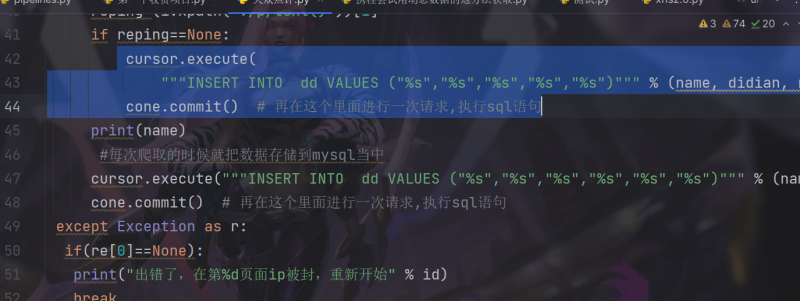
成功登录以后即可为心所欲,在页面爬取时,因为页面的数据是动态加载的,所以我们还需要一些js的操作,每隔5秒自动向下滑动滑轮一定距离,是的数据远远不断的刷新,判断当前页面是否到底,只需要判断当前页面的高度是否有改变,如果一直没变,则说明数据爬取完毕,任务结束

点击空白处退出提示



语言技术
Python
使用了selenium,因为小红书的反爬机制很强,所以填了一个stain.js的文件避免被封掉ip
成功登录以后即可为心所欲,在页面爬取时,因为页面的数据是动态加载的,所以我们还需要一些js的操作,每隔5秒自动向下滑动滑轮一定距离,是的数据远远不断的刷新,判断当前页面是否到底,只需要判断当前页面的高度是否有改变,如果一直没变,则说明数据爬取完毕,任务结束
评论