

0
1
2
3
4
5

2018-05-01 -2023-01-20作业帮数据后端开发
前期负责作业帮广告平台的数据(千万日活,PB级数据)需求开发, 广告平台的数仓建设(0到1参与), Druid OLAP引擎二次开发。后期参与公司公司数据平台建设(任务调度系统开发(即席查询功能,Presto), 日志收集系统的开发(全部后端开发), 数据地图开发(数据治理平台,0到1参与), 数据湖(DeltaLake) 建设)
2015-08-01 -2018-05-01美国径点科技后端研发
负责公司产品的后端开发,公司产品:SharePoint 的数据管理软件,负责数据细粒度备份和还原
2012-09-01 - 2016-06-30大连工业大学计算机科学与技术本科

背景:作业帮是目前用户数最多的K12在线教育平台,而其中的大部分用户都是拍照搜题用户,拍搜 用户转化为直播课用户的效率对于公司来说非常重要,基于这个需求,公司搭建到端内营销平台,而 对于端内营销平台数据是平台优化、判断效率和指导运营工作的利刃 端内营销平台负责将将在作业帮APP端内投放作业帮课程广告,将作业帮APP内的拍搜用户转化为作 业帮直播课用户,而其中广告投放策略、广告投放效果等依赖数据处理和分析 负责:数据需要的开发工作,离线数仓的建设,从0到1搭建,Druid的二次开发和平台维护(druid监控 优化、物化视图优化、精确UV实现、版本回退等) 技术栈:Druid(Apache druid, 一个OLAP, 不是阿里druid)、Kafka、Spark、Redis、Java
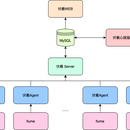
背景:公司各个业务线,会生产很多的日志,包括前端的打点上报日志、监控日志、后台的埋点日志 和业务系统的运行日志等,这些日志分布在不同的机器上,会做不同的处理,包括日志检索、性能监控、ETL入库等,这些操作都需要把日志采集到不同的服务中去,包括Kafka、hive、hdfs和ES等。这 些操作就需要一个统一的平台来进行处理,为了解决这一个问题,我们开发了日志收集平台。 负责:平台的方案设计,整个后端系统的开发, Flume二次开发(传输速率限制,大日志过滤,传输进度, 日志done标记,COS、OSS和BOS的sink组件,支持备用kafka集群等) 技术栈:Python、Flume、Tornado(Python web框架)、JAVA
背景:随着数据中台的数据沉淀,整个数据中台的数据分布在不同的集群、不同的表中。对于数据使 用着来说,当前有那些表,怎样查询这些表,是一个问题。对于数仓来说,表的来源有那些,表是否 就绪,怎么方便的修改表等,是一个问题。而对于数据中台来说,怎样给用户赋权,怎样规范表的创 建,怎样管理表和数据的生命周期等,是一个问题。为了解决这个问题,自研了数据地图这个平台。 负责:部分功能开发(Druid元数据的接入,HIVE元数据接入,血缘管理,表和数据生命周期管理和元 数据管理(表创建和修改, hive和druid),表热度监控,表存储大小监控) 负责:部分功能开发(Druid元数据的接入,HIVE元数据接入,血缘管理,表和数据生命周期管理和元 数据管理(表创建和修改, hive和druid),表热度监控,表存储大小监控) 技术栈:Python, Tornado(Python web框架), JAVA