

0
1
2
3
4
5
我毕业于苏州大学,在百度实习过。
熟悉常用机器学习算法,如逻辑斯谛回归、SVM、朴素贝叶斯等;
熟悉常用神经网络模型,如CNN、RNN、Transformer等;
熟悉常用预训练模型,如BERT、RoBERTa、ERNIE、ALBERT等;
熟悉Python、C++、Shell,了解Java;
熟悉Pytorch、PaddlePaddle、Numpy、Pandas、XGBoost等工具,熟悉Hadoop Streaming;
2021-09-29 -2022-03-14百度算法工程师
优化图搜文本相关性模型 背景:在图片搜索业务场景下,计算用户query和图片资源在文本维度的相关性,指导排序。 问题:分析线上问题时发现,存在大量图片虚假标题标签,导致人审率过大的问题;同时基线模型很难解决用户query和图片title相似但实体不同的文本对,例如“杨幂照片”和“杨幂和刘诗诗”,模型容易判断文本对为匹配; 行动:通过分析图片文本维度的特征,从引入领域post-pretrain、核心term匹配交互、字词embedding混合等方法进行优化相关性模型。 数据集:75w rank训练集、10w rank测试集 领域post-pretrain:使用通用搜索预训练模型为热启,在90亿图搜多域数据(额外引入点击域)上进行字级别post-pretrain,训练任务为MLM+NSP。使用post-pretrain模型为热启,在训练集上进行pointwise的finetune(训练集的title额外引入图片的ocr/文字内容域)。在测试集上pnr达到2.621,超过基线的2.530。 核心term匹配交互:在原始Ernie结构上增加了一层核心term匹配交互层,通过文本对
2020-09-01 - 2022-03-14苏州大学计算机技术硕士
EMNLP 2021 已录用 (CCF-B) ICTAI 2022 已录用(CCF-C)

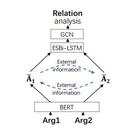
本文通过实验探究在隐式篇章关系识别任务中存在的表意不全问题,并提出一种基于交互注意力的掩码语言 模型(IAMLM),将 IAMLM 与 RoBERTa 分类模型结合,集成到多任务学习框架中; 该方法计算论元之间的交互注意力矩阵,并依赖交互注意力动态选择论元之间高关联性的关键词项进行 遮蔽、掩码重构,将预测关键词的任务作为辅助任务,从而形成更有针对性的数据增强; 与 RoBERTa 作为 baseline 对比,在 Temporal、 Comparison、 Contingency 和 Expansion 分别提升了 6.56%、 3.21%、 6.46%和 2.74%。
校园地图导航,负责算法设计,界面绘制,在图形界面上绘制校园两个地点路径 使用QT进行开发,C++,底杰斯特拉算法 QT可视化路径是难点,实现最短路径算法和可视化界面融合。
任务: 在图片搜索业务场景下,计算 query 和图片资源在文本维度的相关性,指导排序。 挑战: 分析线上问题时发现,基线模型很难解决 query 和 title(选取域 =title realtitle alt ct0)相似但实 体不同的文本对,例如“杨幂照片”和“杨幂和刘诗诗”,模型容易判断文本对为匹配。 优化: 从引入领域 post-pretrain、核心 term 匹配交互、字词 embedding 混合等方法进行优化相关性模 型。 • 数据集: 75w Rank 训练集, 10w Rank 测试集 效果: 考虑线上应用的性能,将 24 层模型蒸馏为 4 层模型。采用数据蒸馏的方式,预测 1.2E 数据打 分,使用 pointwise 进行训练,指标为 auc:0.846|pnr:2.907(相比基线 +0.063|+0.273),已完成上线。 技术: Python, Hadoop, Shell, Pre-training, Transformers, Text Matching

