




任务: 在图片搜索业务场景下,计算 query 和图片资源在文本维度的相关性,指导排序。
挑战: 分析线上问题时发现,基线模型很难解决 query 和 title(选取域 =title realtitle alt ct0)相似但实
体不同的文本对,例如“杨幂照片”和“杨幂和刘诗诗”,模型容易判断文本对为匹配。
优化: 从引入领域 post-pretrain、核心 term 匹配交互、字词 embedding 混合等方法进行优化相关性模
型。
• 数据集: 75w Rank 训练集, 10w Rank 测试集
效果: 考虑线上应用的性能,将 24 层模型蒸馏为 4 层模型。采用数据蒸馏的方式,预测 1.2E 数据打
分,使用 pointwise 进行训练,指标为 auc:0.846|pnr:2.907(相比基线 +0.063|+0.273),已完成上线。
技术: Python, Hadoop, Shell, Pre-training, Transformers, Text Matching
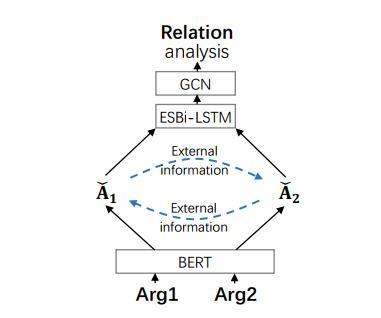
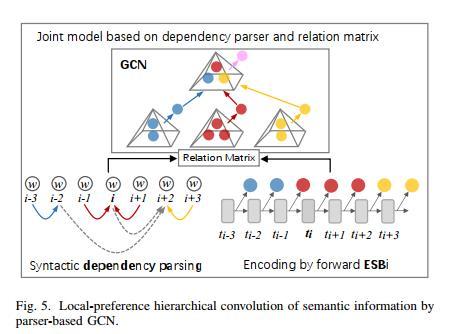

点击空白处退出提示
评论