





'''
目标网站:https://www.1ppt.com/moban/
需求:
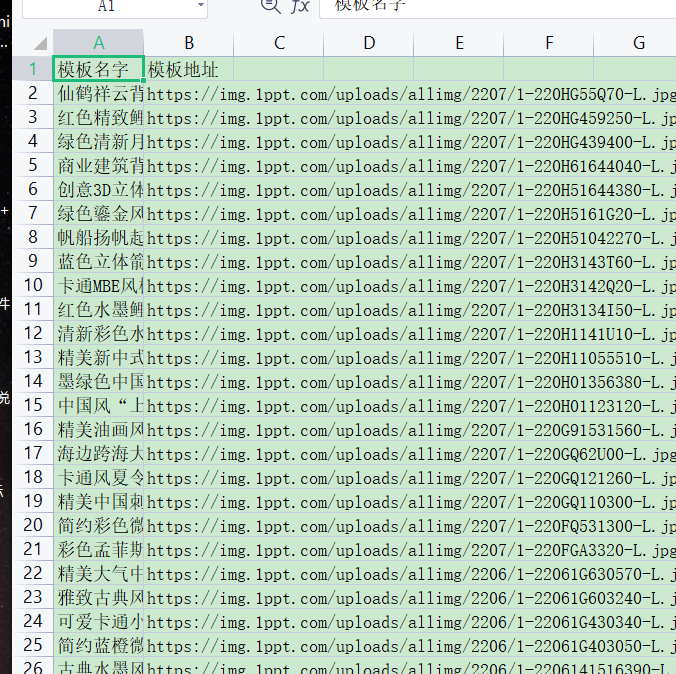
1、用多线程爬取前10页模板名字和模板详情页链接
2、把模板名字和模板详情页链接保存到模板.csv文件里面
https://www.1ppt.com/moban/ppt_moban_2.html
https://www.1ppt.com/moban/ppt_moban_3.html
'''
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
import requests
import threading#导入多线程库
import csv
from queue import Queue #导入队列的库
# from bs4 import BeautifulSoup
from lxml import html
import time
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
etree = html.etree
class One(threading.Thread):
la7 = []
def __init__(self, url, data):
super().__init__()
self.zhen2 = url
self.chao3 = data
def run(self):
while True:
if self.zhen2.empty():
break
else:
zhen3 = self.zhen2.get()
# print(zhen3)
tm = requests.get(zhen3, headers=header)
tm.encoding = 'gb2312'
td = tm.text
# print(td)
la2 = etree.HTML(td)
la3 = la2.xpath('//ul[@class="tplist"]/li')
for t in la3:
la6 = {}
la5 = t.xpath('./a/img/@src')[0]
la4 = t.xpath('./a/img/@alt')[0]
la6['模板名字'] = la4
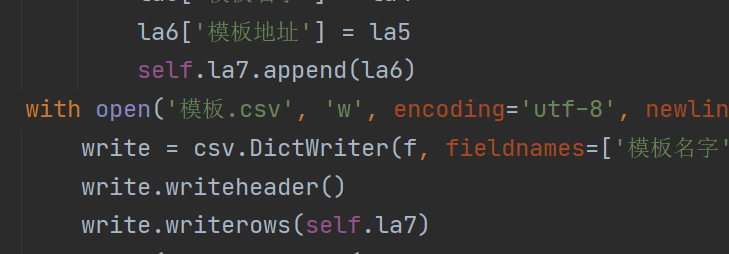
la6['模板地址'] = la5
self.la7.append(la6)
with open('模板.csv', 'w', encoding='utf-8', newline='')as f:
write = csv.DictWriter(f, fieldnames=['模板名字', '模板地址'])
write.writeheader()
write.writerows(self.la7)
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
# la = BeautifulSoup(td, 'lxml') #转为它这个对象
# a = la.find('ul', class_="tplist")
# jiem2 = a.find_all('li')
# print(len(jiem2))
if __name__ == '__main__': #程序主入口
#1、创建url队列
tom = Queue()
#2、创建一个放模板名字和模板的链接的队列
jemi = Queue()
tom.put('https://www.1ppt.com/moban/') #生产者
for i in range(2, 11):
look = f'https://www.1ppt.com/moban/ppt_moban_{i}.html'
tom.put(look)
# print(tom)
for i in range(3): #分为三个进程
t = One(tom, jemi)
t.start() #启动进程
# t.join()

点击空白处退出提示
评论