





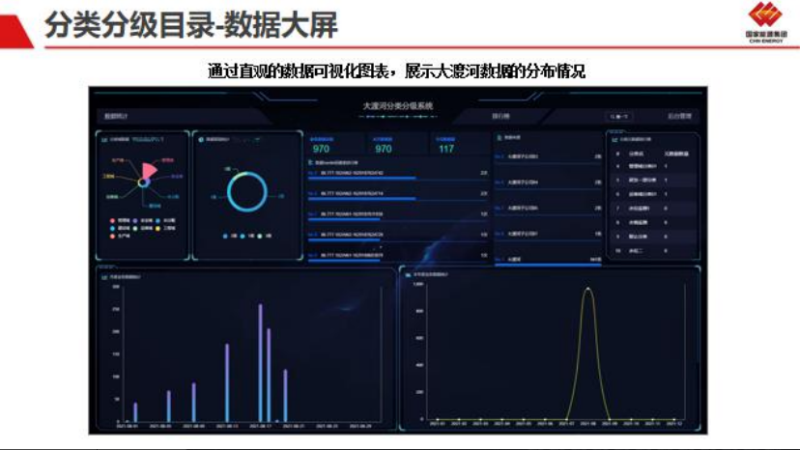
该项目是公司与成都国能大渡河大数据服务有限公司合作完成。主要是帮助成都流域各个水电站
的大量杂乱数据按照提前制定好的行业标准进行分类分级处理。
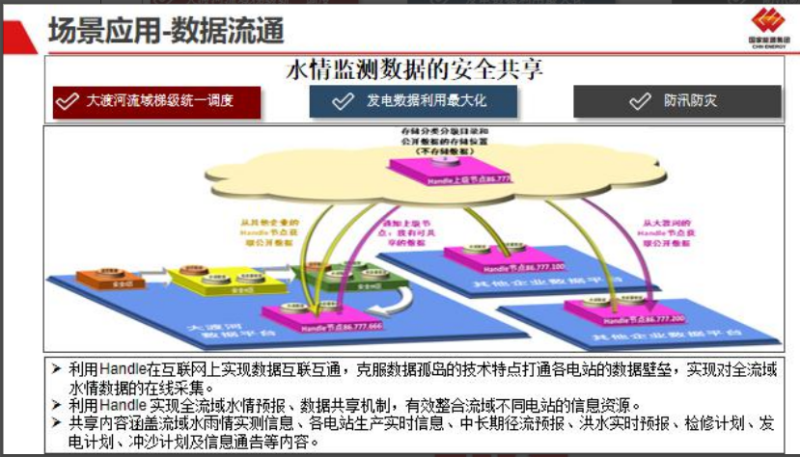
该项目离线数据是通过 FileBeat 从客户服务器进行抓取实时数据传输至数据治理平台大数据集群
内 kafka 中间件,最大的一个主题(
topic)数据量可每秒可达 600 条实时数据,高峰可达 1000-3000 条左
右数据,每天一类水量数据可达亿级别数据,数据体量可达 TB 级别,然后实时数据通过 Flink 和
SparkStreaming 实时计算引擎,将数据清洗进实时数仓,
ods->dwd->dws->ads,将数据通过分层清晰进 hbase
和 redis,es 等实时查询引擎供实时业务查询,然后再通过 sparksql 离线引擎将 Hbase 中数据按照每天的
计算任务指标定时清洗进 HDFS,通过 Hive 建立外表供机器学习和业务查询。

点击空白处退出提示
评论