





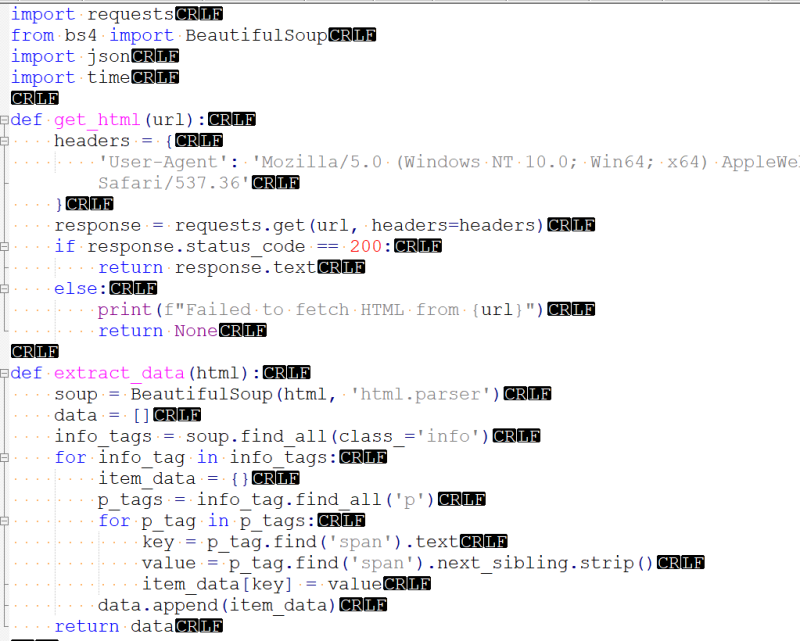
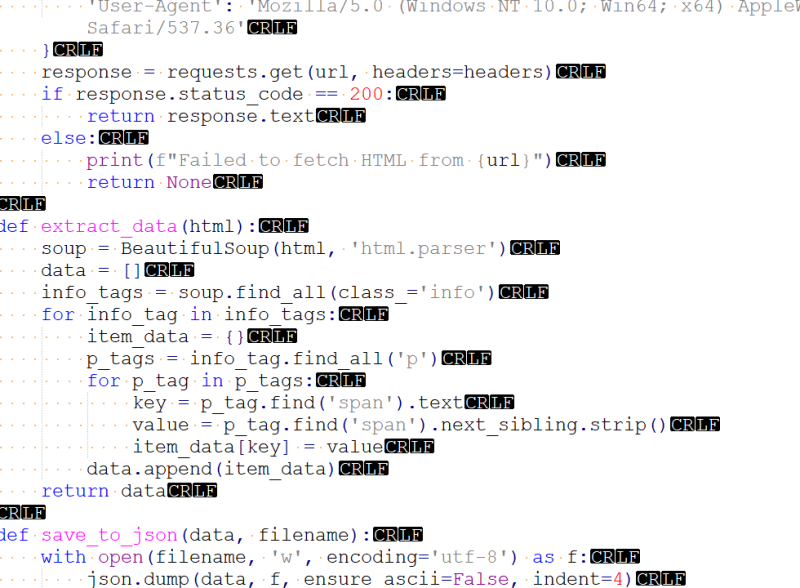
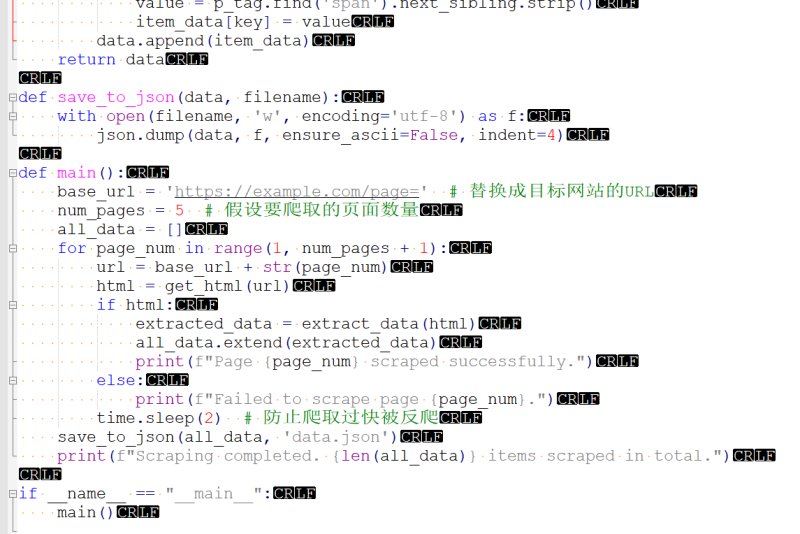
【60%】项目分为多个功能模块,主要实现了自动化爬取指定网站的信息,并将数据存储为JSON格式文件。
【40%】我负责编写Python脚本,利用Requests库发送HTTP请求获取网页内容,使用BeautifulSoup库解析HTML页面,提取所需信息,并将信息存储为JSON文件。最终,成功实现了自动化爬取指定网站信息的功能。
难点:网站反爬机制和数据结构解析。通过设置合适的请求头模拟人类操作、使用代理IP等方法规避反爬机制;通过深入了解HTML结构和BeautifulSoup库的用法,解析并提取所需信息。

点击空白处退出提示
评论