





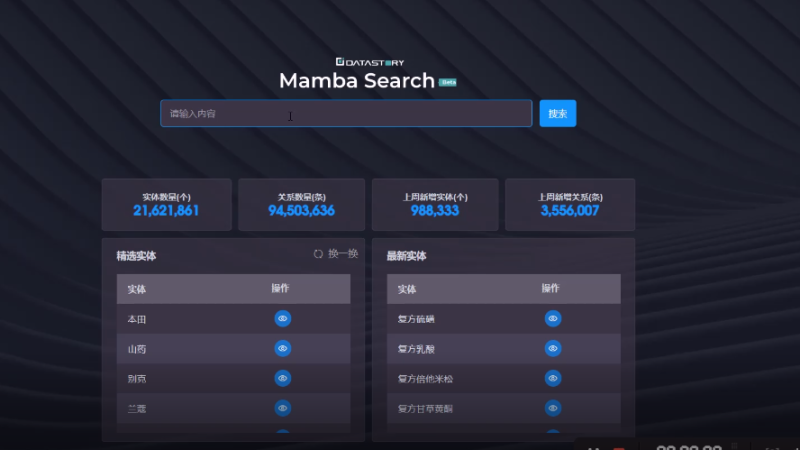
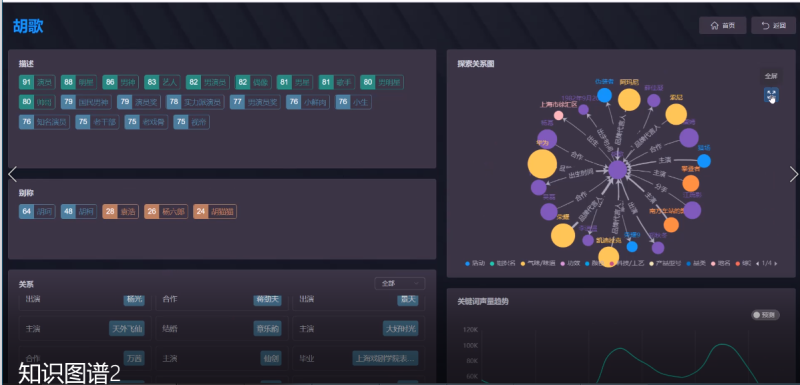
基于公司在食品饮料、美妆日化、家电、美容仪器等多个领域积累多年的
文本数据构建一个千万实体 上亿关系的开放领域的知识图谱。先通过实体抽取算法
Bert-CRF 识别出文本中对应的实体,然后通过判断两个实体之间是否有关系和开放
知识抽取两种关系抽取方法识别出主谓宾关系。最后将知识抽取的结果输入到知识融
合算子,合并所有的知识并通过码表方式对实体和关系归一化,基于规则过滤无效知
识并设置实体黑名单等操作后最后输出节点和边的两份 CSV 文件写入知识图谱。其中
节点和边的结果文件信息包含名称、类型、实体强度、实体置信度、最早时间、最晚
时间等字段。

点击空白处退出提示
评论