首页
程序员
解决方案
招聘用人
云端工作
自由工作、远程工作
项目研发
需求梳理
规划落地您的想法
整包开发
一站式软件开发
作品
发布需求
开发者入驻
APP
登录
/
注册
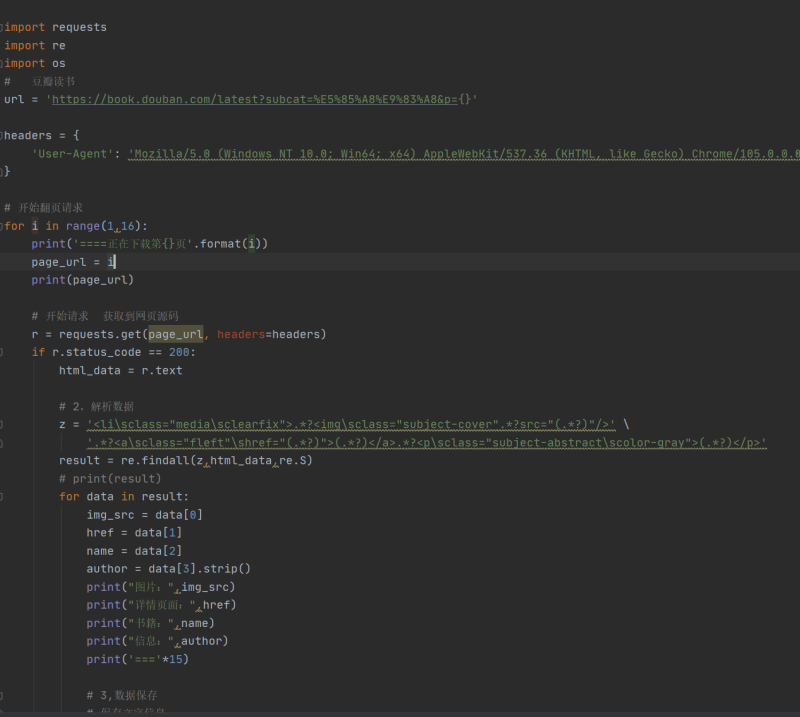
豆瓣新书的爬取
我要开发同款
sc3
2022年10月20日
212阅读
功能介绍
1.项目分为翻页,解析,保留等模块
2.我们要爬取新书的图片链接,详情链接,名称,
并将其保存到txt文本中,将图片保存到一个新建的文件夹中
3.难点是翻页的实现,参数的分析,和正则解析的使用
示例图片
声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!
下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态
前往安装
评论
评论
重点城市程序员兼职推荐
北京程序员兼职
上海程序员兼职
深圳程序员兼职
广州程序员兼职
杭州程序员兼职
成都程序员兼职
南京程序员兼职
武汉程序员兼职
西安程序员兼职
重庆程序员兼职
郑州程序员兼职
长沙程序员兼职
苏州程序员兼职
合肥程序员兼职
厦门程序员兼职
济南 程序员兼职
青岛程序员兼职
天津程序员兼职
大连程序员兼职
福州程序员兼职
石家庄程序员兼职
沈阳程序员兼职
太原程序员兼职
无锡程序员兼职
南昌程序员兼职
哈尔滨程序员兼职
南宁程序员兼职
珠海程序员兼职
宁波程序员兼职
昆明程序员兼职
东莞程序员兼职
贵阳程序员兼职
美国程序员兼职
长春程序员兼职
温州程序员兼职
佛山程序员兼职
常州程序员兼职
呼和浩特程序员兼职
兰州程序员兼职
乌鲁木齐程序员兼职
中山程序员兼职
海口程序员兼职
洛阳程序员兼职
更多
重点岗位程序员兼职推荐
C++兼职
Rust兼职
小程序兼职
cocos2d-x兼职
Unity3D兼职
DBA兼职
运维兼职
测试兼职
Go兼职
UE设计师兼职
全栈兼职
技术创始人兼职
CTO兼职
架构师兼职
产品经理兼职
Java兼职
PHP兼职
C兼职
C#兼职
Python兼职
Ruby兼职
Node.js兼职
Android兼职
iOS兼职
前端兼职
UI设计师兼职
原画师兼职
项目经理兼职
Vibe Coding兼职
HarmonyOS兼职
区块链兼职
人工智能兼职
硬件开发兼职
移动其他兼职
更多








评论