


爬取某网站案例,步骤如下:
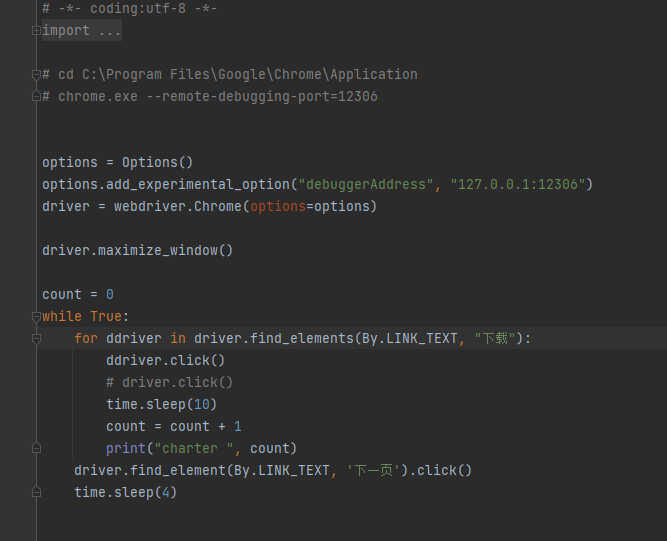
1、手动在cmd命令行下启动chrome.exe --remote-debugging-port=12306 -new-window http://www.cnemc.cn/sssj/
2、然后手动登录,筛选条件。然后启动main.py,开始自动下载文件,10秒一次,(未做反爬措施,小玩具,~~莫见怪~~。)
注:依赖的库为selenium、单次使用只可以爬取100份文书,更多数量容易封号!!!!

点击空白处退出提示



爬取某网站案例,步骤如下:
1、手动在cmd命令行下启动chrome.exe --remote-debugging-port=12306 -new-window http://www.cnemc.cn/sssj/
2、然后手动登录,筛选条件。然后启动main.py,开始自动下载文件,10秒一次,(未做反爬措施,小玩具,~~莫见怪~~。)
注:依赖的库为selenium、单次使用只可以爬取100份文书,更多数量容易封号!!!!
评论