





分析目标网页,找到数据所在位置。豆瓣电影Top250的网页结构很规整,数据所在DOM节点位置清晰可辨。
2. 选择爬虫工具。这里我选择了Scrapy,它是Python的一个强大的爬虫框架,可以轻松编写复杂的爬虫程序。
3. 创建Scrapy项目和Spider。使用命令`scrapy startproject douban_movie`和`scrapy genspider top250 douban.com`。
运行Spider,获取数据。使用命令`scrapy crawl top250`运行Spider,得到电影信息列表。
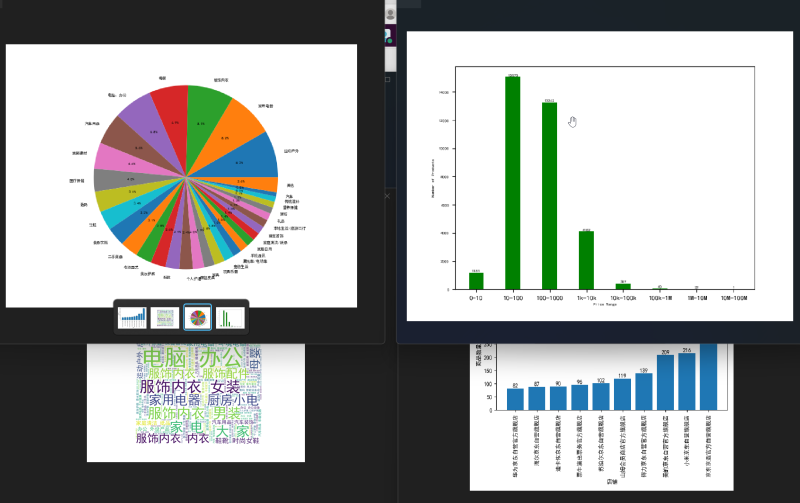
6. 数据存储与展示。将数据保存到CSV文件,然后使用Matplotlib绘制电影评分分布直方图,并用Pandas制作电影top10排行榜。
这个爬虫项目让我熟练掌握了Scrapy的使用,学会了解析复杂网页的技巧,并将爬取的数据进行了简单的统计分析与展示。Scrapy是一个非常强大的爬虫框架,利用它可以轻松开发各种爬虫项目。

点击空白处退出提示
评论