


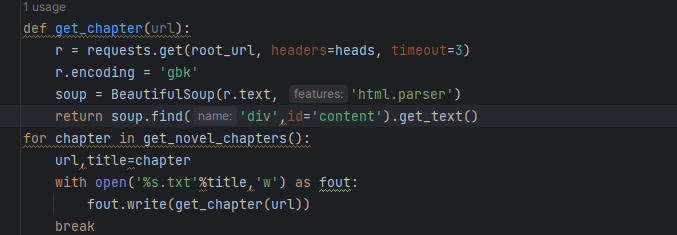
以《院士重生》为例子,爬取对应的全部章节存储在txt文件中
#url是要下载的目标网页的url
#伪装自己,尽量使服务器认为我是从浏览器访问的。可在request函数参数中写入headers timeout来使得服务器认为我是从浏览器访问的
#处理结果
#解析相应的数据
#是否保存'''

点击空白处退出提示



以《院士重生》为例子,爬取对应的全部章节存储在txt文件中
#url是要下载的目标网页的url
#伪装自己,尽量使服务器认为我是从浏览器访问的。可在request函数参数中写入headers timeout来使得服务器认为我是从浏览器访问的
#处理结果
#解析相应的数据
#是否保存'''

评论