

普通话借工具书面交流
0
1
2
3
4
5

一、专业技能
(1)开发语言:Java(多线程/分布式开发)、Scala(Spark/Flink编程)、Shell(脚本)
(2)大数据生态:Hadoop(HDFS/YARN)、Spark SQL/Streaming、Flink状态管理、Kafka消息队列、GeoMesa大数据平台
(3)数据治理:数据仓库分层设计(ODS/DWD/DWS/ADS/DM)、ETL工具和流程优化、Hive SQL调优
(4)工具与框架:DolphinScheduler/Azkaban/oozie(任务调度)、DataX/Kettle(数据同步)、Davinci/CBoard(可视化)
(5)OLAP分析:ClickHouse、GreenPlum
(6)信创生态:了解国产化生态,有丰富的国产化系统建设经验。
(7)以核心成员身份,参加过金税四期国家级的大数据项目、3个公司的大数据重点项目,多次实现大数据平台0-1的建设,在大数据领域有丰富的设计、开发经验。
二、自我评价
技术驱动:深耕大数据领域,擅长通过技术优化解决业务痛点,如提升数据处理效率、降低资源消耗;
结果导向:主导多个千万级数据项目落地,从需求分析到交付全流程把控,确保项目高质量完成;
持续学习:关注数据湖、实时数仓、DATA+AI等新技术方向,探索Doris/StarRocks等OLAP引擎的实践应用;
学习能力:大学期间1年考下英语四六级、计算机二级和四级,自主钻研和学习能力很强。
2019-03-18 -2022-06-24前大象慧云高级大数据开发已认证
一、平台搭建与优化 (1)大数据平台开发与维护 负责Hadoop、Flink、Spark等分布式计算平台的部署、监控及性能调优,解决集群告警与故障1。 优化HDFS存储策略、YARN资源分配,提升平台稳定性与扩展性(如Kafka扩容方案设计)。 (2)实时/离线计算系统建设 搭建实时数据处理链路:通过Flink/Kafka实现日志聚合、流式数据清洗及实时分析。 构建离线数仓:基于Hive、Spark SQL开发ETL任务,支持T+1报表生成与历史数据分析。 二、数据全流程治理 (1)数据采集与清洗 使用Flume/Sqoop/Kafka采集多源数据(日志、数据库BinLog等),并完成字段映射、空值处理等标准化操作。 开发数据质量规则,监控数据一致性、完整性,保障下游业务用数准确性。 (2)数仓架构设计与优化 分层建模:设计ODS原始层、DWD明细层、DWS聚合层,支持星型/雪花模型等主题域划分。 提升查询效率:优化Hive SQL执行计划、Impala/Presto参数配置,降低大数据量下的响应延迟。 三、业务支持与协同 (1)数据分析与可视化 对接BI需求:开发
2008-09-01 - 2012-06-30河北北方学院信息管理与信息系统本科已认证
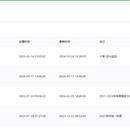
1、方案面向数据开发人员,解决了海量数据分析统计,解决关系型数据库针对海量数据分析慢的问题 2、Kappa架构的大数据方案,实现流批一体;Lambda架构的大数据方案,离线和实时分离的数据仓库方案。 3、技术选型: (1)数据源 → Kafka → Flink实时计算 → Clickhouse → API/BI展示 (2)数据源 → Datax → Hive/Spark SQL → 关系型数据库 → API/BI展示



