





1. 手动操作一遍,看看每个板块是不是动态加载,有没有带参数
2. 在终端里 scrapy startproject wanyi 构建wanyi文档,cd进入文档,scrapy genspider wanyipy www.xxx.com 在目录下创建一个爬虫文件
3. 在items文件里建立两个对象(标题和内容)
4. 首先通过xpath爬取到首页中每个模块的href,接着对每一个板块的url进行请求发送
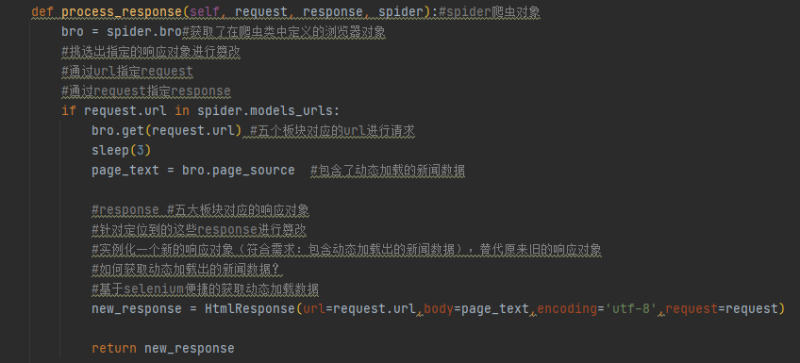
5. 发现每一个板块对应的新闻标题相关的内容都是动态加载,所以得导入selenium库来进行发送请求并在middlewares里拦截并篡改响应数据,再return出新的请求
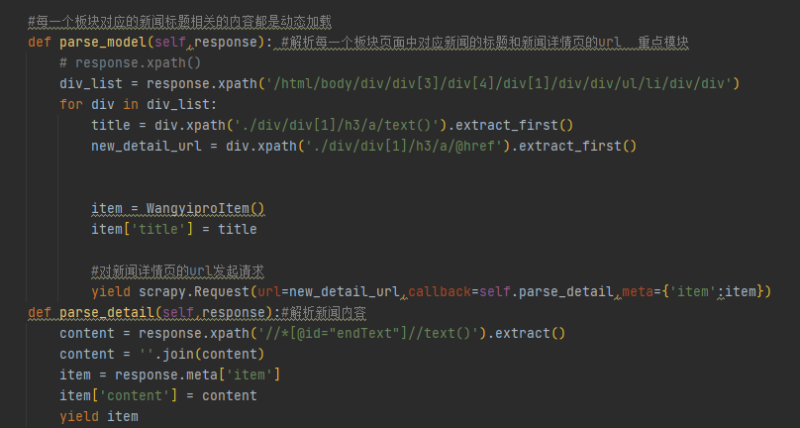
6. 依次遍历通过xpath获取到每个模块下的标题和标题链接
7. 请求标题链接再通过xpath获取到对应标题下的新闻内容,import items库实例化一个item对象,赋值上标题和内容的值 再yield出去到管道类里边
8. 最后在pipelines文件里进行存储数据的操作

点击空白处退出提示
评论