





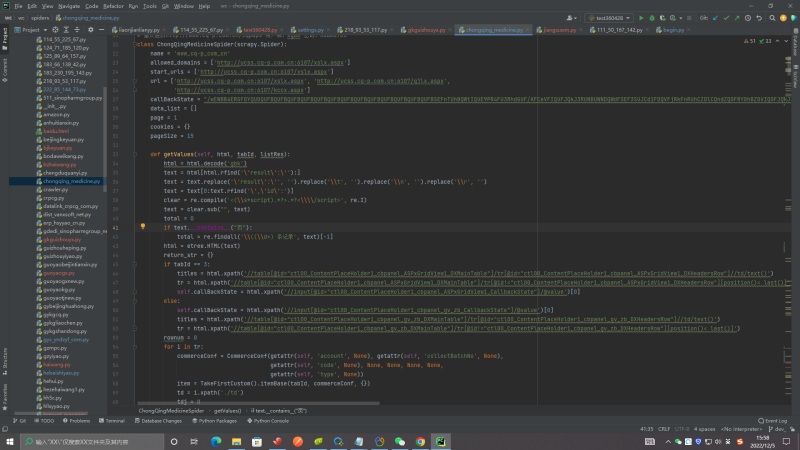
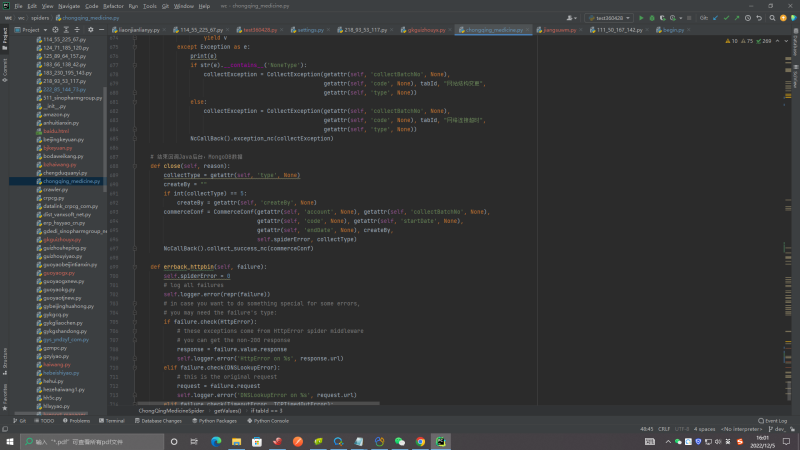
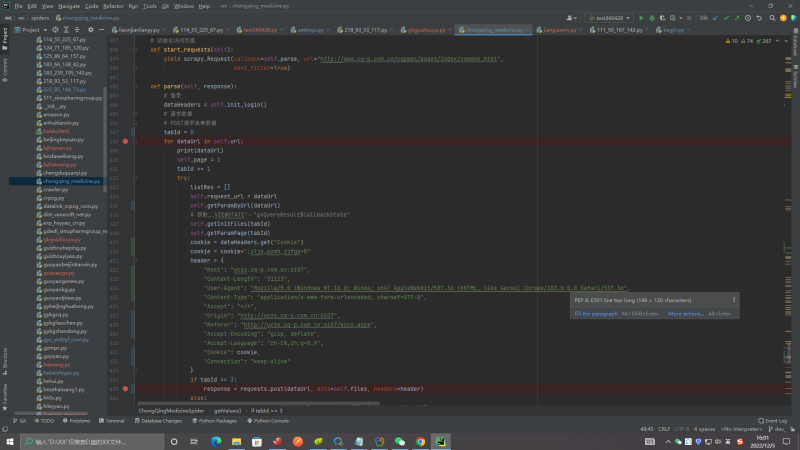
1.项目需求是获取该网站内所有数据并保存到指定数据库,这里我把拿到的数据放到了mongodb,模块主要是处理登入模块,获取cookie和token模块,处理数据请求参数模块,数据处理模块,异常处理模块等
2.该爬虫是我个人开发,主要基于Scrapy框架实现的,用到的技术栈主要有scrapy,selenium,phatomjs,requests,XPath解析器,BeautifulSoup解析器,PyQuery CSS解析器抽取结构化数据, 使用正则表达式抽取非结构化数据等
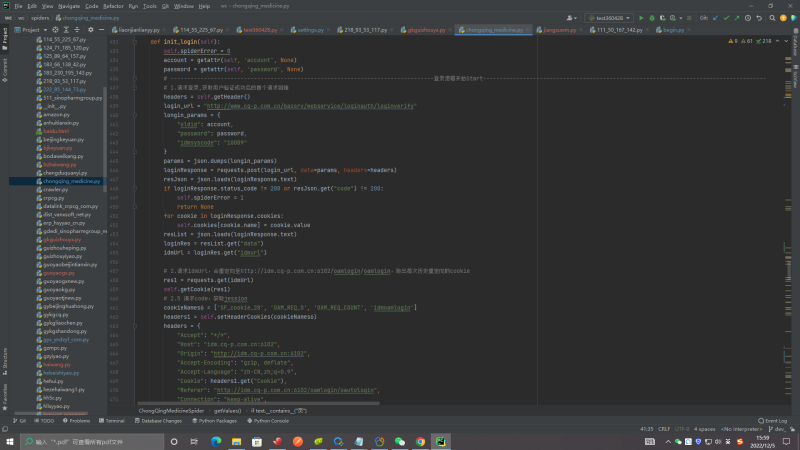
3.该网站技术难点主要体现在获取登入所需的cookie,一共进行了6次重定向且每次重定向不能让他自动跳转,每次重定向会拿到一个cookie片段,最后拼接在一起,最后还需做一个加密处理才是能使用的cookie!!!

点击空白处退出提示
评论