





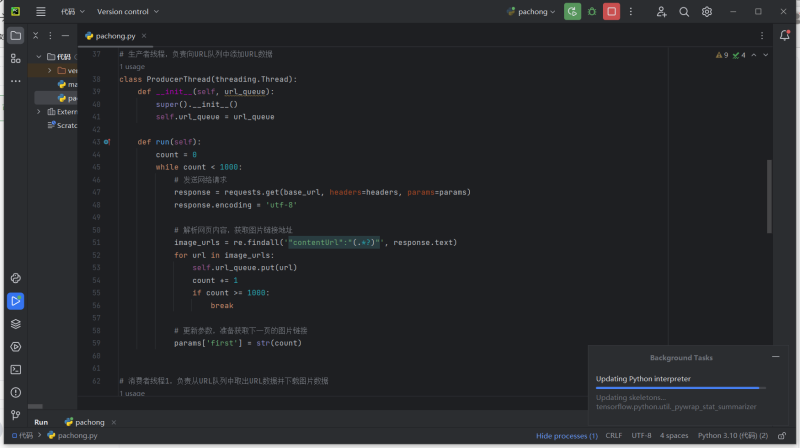
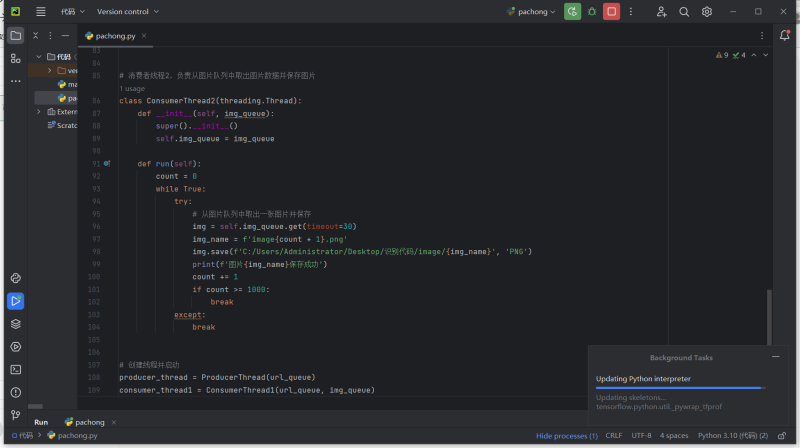
爬虫爬取图片实现了以下主要功能:
在指定的网站中获取特定内容的URL(通常是图片);
使用HTTP协议的GET方法,通过访问这些URL下载图片到本地;
可以使用多线程或异步处理技术,提高图片下载的效率;
为了避免反扒机制的限制,需要模拟浏览器的行为,包括设置User-Agent、Referer和Cookie等信息,以及限制访问频率等;
可以使用机器学习技术(如图像分类算法)对下载的图片进行一定的处理,实现更加自动化的爬虫;
总的来说,爬虫爬取图片的实现主要涉及到获取和下载图片、处理反扒机制、提高下载效率等方面。

点击空白处退出提示
评论