

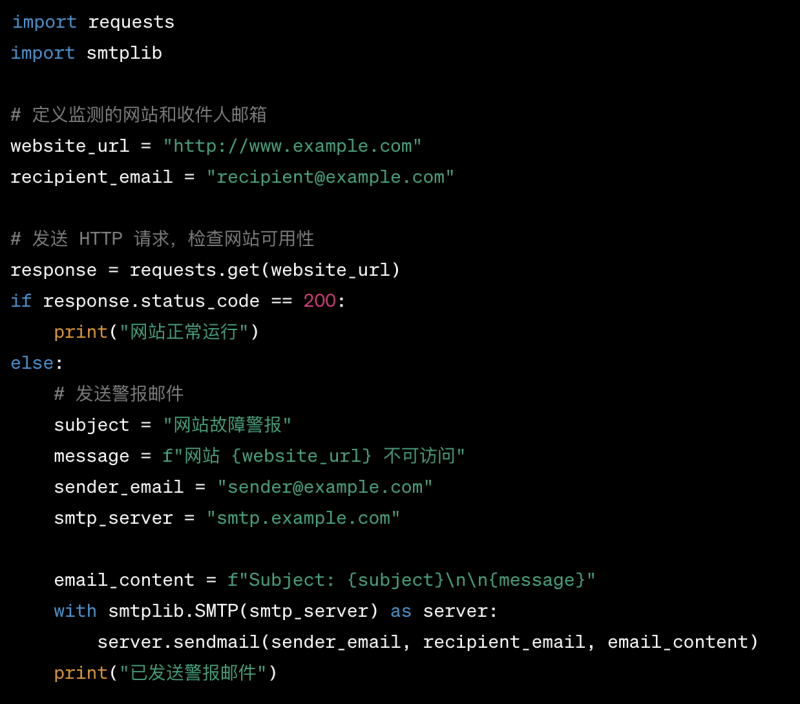
在项目中,我们建立了一套故障监测与恢复的工作流程。我们利用监控工具,如Nagios、Zabbix或Prometheus,实时监测系统的关键指标和状态。当系统出现异常情况时,我们通过配置警报规则,及时通知运维团队进行处理。
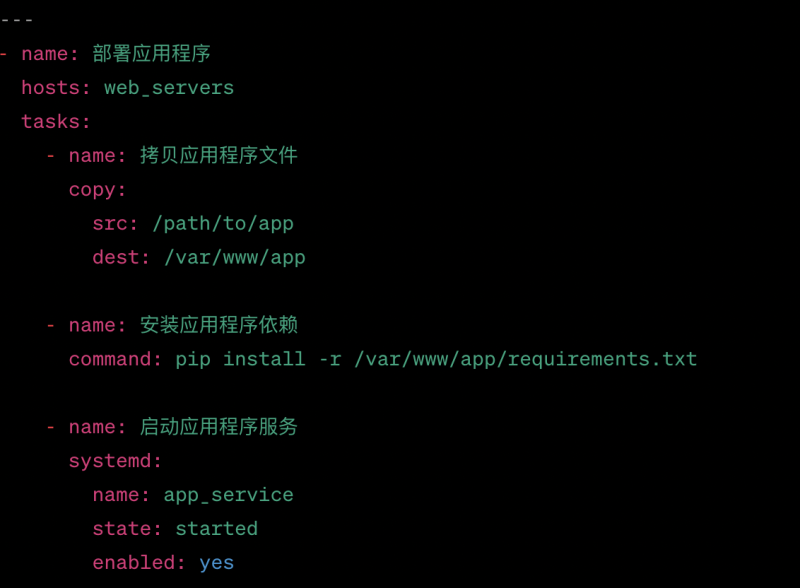
为了自动化故障恢复过程,我们采用了脚本和自动化工具。根据不同类型的故障,我们编写了相应的脚本来自动执行必要的恢复操作,如重启服务、调整配置或重新部署应用程序。我们还结合了配置管理工具,如Ansible或Puppet,来实现自动化的系统配置和环境恢复。

点击空白处退出提示



在项目中,我们建立了一套故障监测与恢复的工作流程。我们利用监控工具,如Nagios、Zabbix或Prometheus,实时监测系统的关键指标和状态。当系统出现异常情况时,我们通过配置警报规则,及时通知运维团队进行处理。
为了自动化故障恢复过程,我们采用了脚本和自动化工具。根据不同类型的故障,我们编写了相应的脚本来自动执行必要的恢复操作,如重启服务、调整配置或重新部署应用程序。我们还结合了配置管理工具,如Ansible或Puppet,来实现自动化的系统配置和环境恢复。
评论