演示地址https://github.com/Ywz2018/AEED-for-speech-enhancement
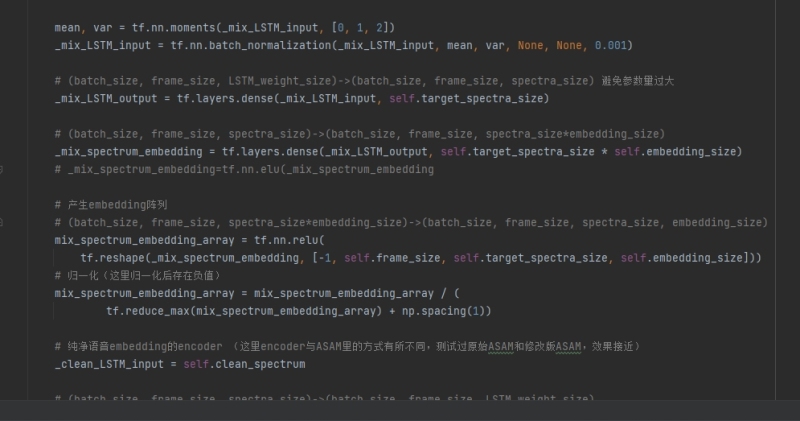
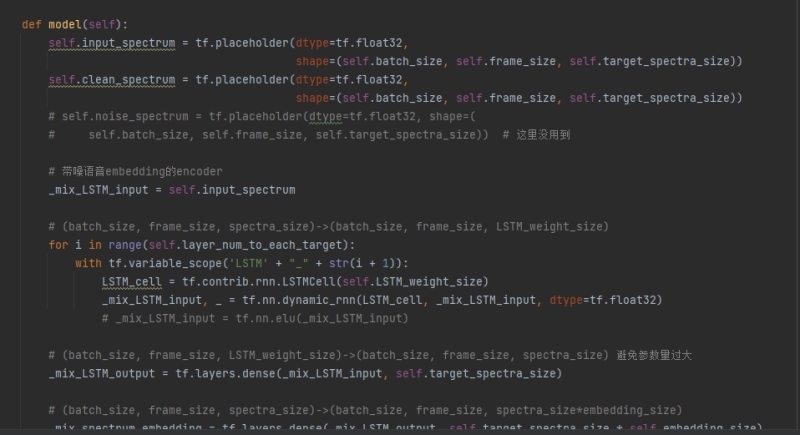
该系统由tensorflow编写,由LSTM生成声音的时频元embbeding矩阵,再用CNN降维还原语谱图 在语音增强方面得到了较好的效果,而且模型参数量较小
评论







评论