


【立项原因】针对HanLP便携版词典配置复杂、缺乏可视化界面的痛点,开发这款桌面端分词工具,解决个人开发者/中小企业文本处理的轻量化需求。
【行业场景】适用于NLP项目原型验证、金融文本分词、自媒体内容预处理等场景,无需复杂配置,导入自定义词典即可快速生成分词结果,提升文本处理效率。

点击空白处退出提示



【立项原因】针对HanLP便携版词典配置复杂、缺乏可视化界面的痛点,开发这款桌面端分词工具,解决个人开发者/中小企业文本处理的轻量化需求。
【行业场景】适用于NLP项目原型验证、金融文本分词、自媒体内容预处理等场景,无需复杂配置,导入自定义词典即可快速生成分词结果,提升文本处理效率。
本工具包含6大核心功能模块:
1. **文本处理模块**:支持手动输入/本地文本导入,兼容UTF-8编码,避免中文乱码;
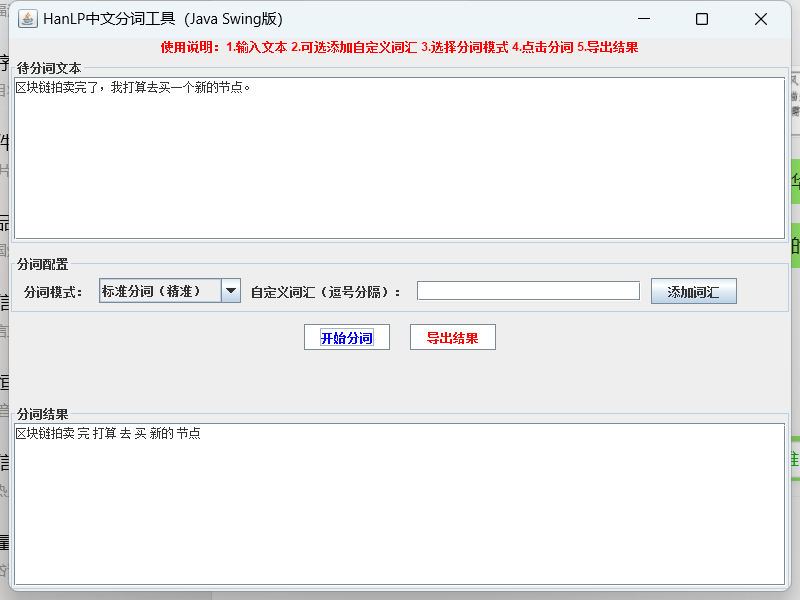
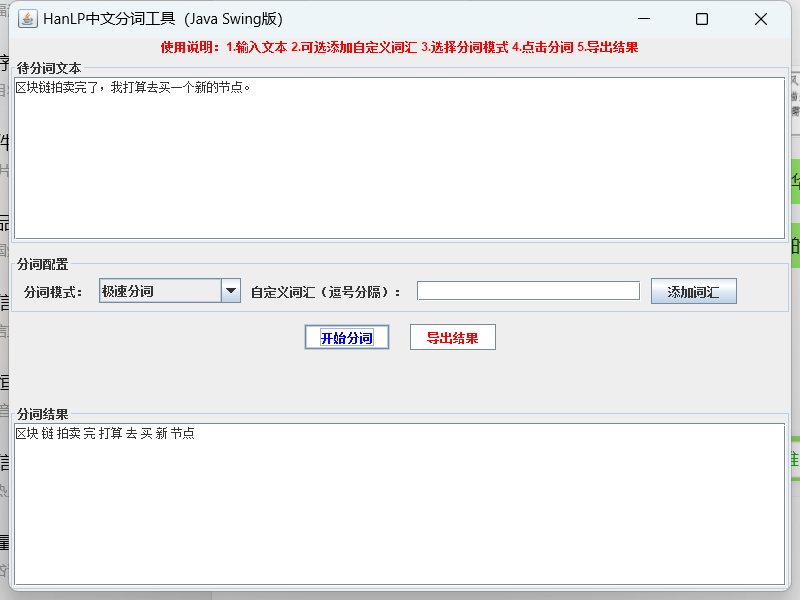
2. **多模式分词**:提供标准、极速、NLP三种分词模式,满足不同场景效率/精度需求;
3. **自定义词典管理**:支持批量导入行业词汇、动态添加新词,适配专业领域分词需求;
4. **停用词过滤**:内置通用停用词表,可一键过滤“的、了、在”等无意义词汇;
5. **结果导出**:分词结果可导出为TXT文件,支持后续数据处理;
6. **可视化界面**:Swing GUI设计,操作简单,无需命令行即可完成分词任务。
整体解决了HanLP便携版无可视化界面、词典配置复杂的痛点,适合个人开发者和中小企业轻量化文本处理需求。
【个人负责任务】独立完成全流程开发:需求分析、Swing界面设计、HanLP API适配、自定义词典加载逻辑、停用词过滤功能、结果导出模块及测试验证。
【技术栈与架构】基于Java SE开发,采用Swing构建桌面GUI,核心依赖HanLP portable-1.8.5,通过Maven管理项目依赖;架构为单桌面应用,无服务端依赖,本地即可运行。
【实现亮点】1. 自动加载HanLP内置词典,无需手动下载词典包,国内访问稳定;2. 适配便携版API,用ViterbiSegment模拟极速分词、开启词性标注模拟NLP模式;3. 用类加载器读取Jar内资源,解决文件路径错误问题。
【技术难点】1. 适配HanLP便携版的API差异,替代缺失的高级分词模式;2. 处理Jar包内资源读取的路径兼容问题;3. 解决中文文本导入/导出的编码乱码问题。



评论