

这是一个专门用于学习Python爬虫的练习项目。目标网站是http://books.toscrape.com/,这是一个全球爬虫开发者常用的练习平台。项目的主要目的是掌握静态网页的数据采集技术,为后续接单做技术储备。业务背景是:许多企业和个人需要从网站上获取公开数据用于市场分析、价格监控等场景,本项目正是模拟了这种需求。

点击空白处退出提示



这是一个专门用于学习Python爬虫的练习项目。目标网站是http://books.toscrape.com/,这是一个全球爬虫开发者常用的练习平台。项目的主要目的是掌握静态网页的数据采集技术,为后续接单做技术储备。业务背景是:许多企业和个人需要从网站上获取公开数据用于市场分析、价格监控等场景,本项目正是模拟了这种需求。
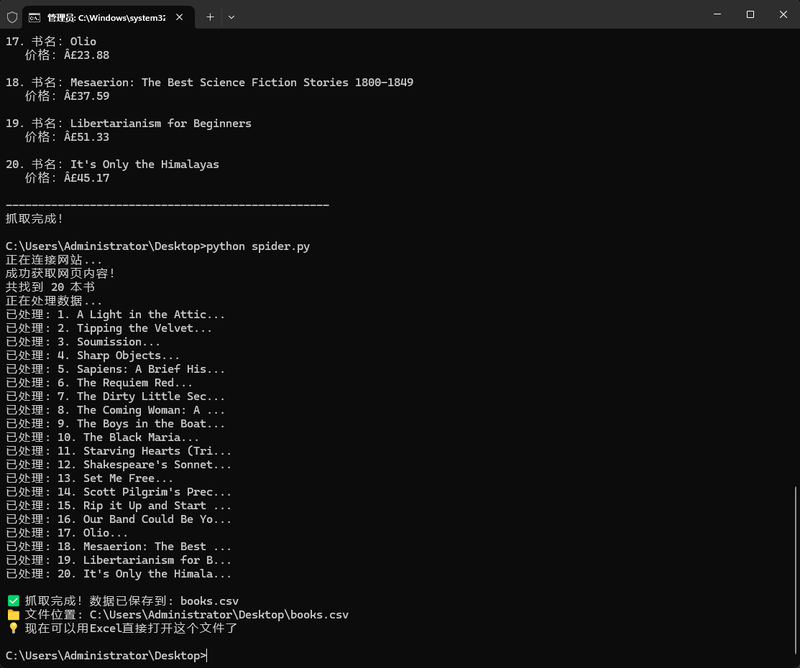
1. 自动抓取功能:程序启动后会自动连接目标网站,获取首页所有图书信息。
2. 数据解析模块:从网页HTML中精准提取图书的完整书名和价格信息。
3. 数据清洗功能:自动处理价格中可能出现的特殊字符(如Â),确保数据整洁。
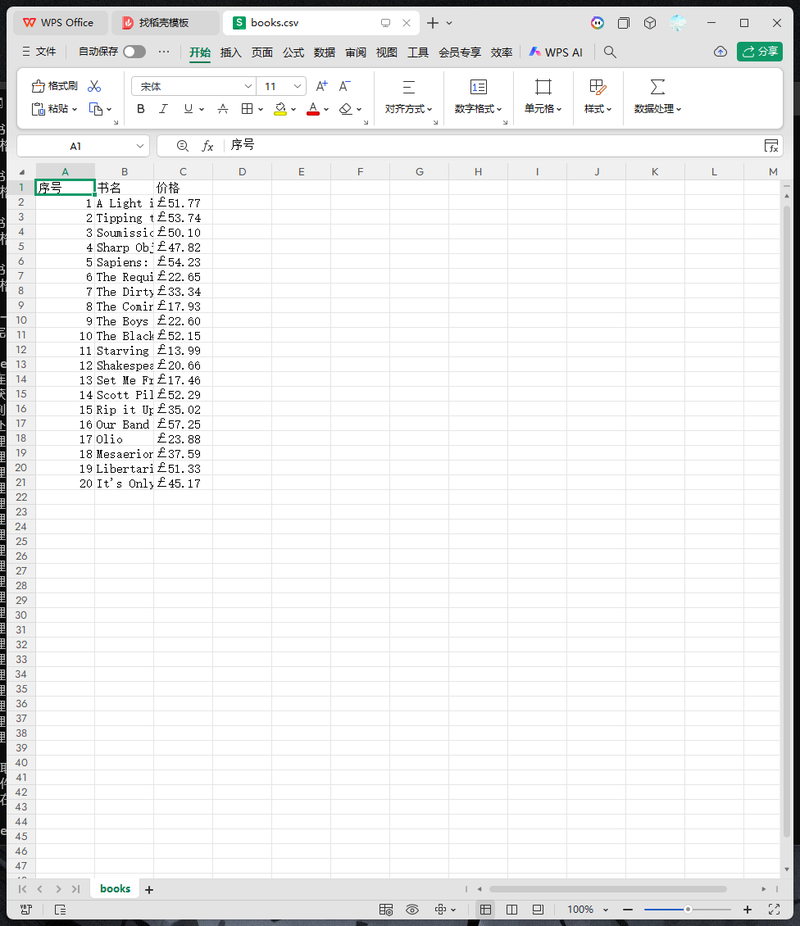
4. 数据存储功能:将抓取到的书名和价格保存为CSV格式文件,可直接用Excel打开。
5. 进度显示功能:运行时在命令行实时显示处理进度,便于用户了解程序运行状态。
6. 错误处理机制:对网络请求失败等情况进行判断并给出友好提示。
我负责了整个项目的独立开发和测试工作。项目使用了Python语言,主要技术栈包括:requests库(发送HTTP请求获取网页)、BeautifulSoup库(解析HTML提取数据)、csv模块(将数据保存为表格文件)。实现亮点:代码结构清晰,每行都有详细注释;加入了请求头伪装,模拟真实浏览器访问;对价格数据进行了清洗,确保输出格式规范;设置了合理的请求延迟,体现专业爬虫的礼貌性。难点在于:初次接触时需要理解HTML标签结构和属性选择,通过多次调试最终成功定位到目标数据。
评论