

立项原因:观看外语直播、视频会议、在线课程时,非母语者无法实时理解内容。现成的字幕方案要么收费、要么延迟大、要么不支持系统音频。
业务背景:跨境直播、YouTube/Twitch 生肉内容、Zoom/Teams 国际会议三大场景都有强需求。市面上同类工具(如 OBS 字幕插件、Google Live Caption)普遍存在"英文输出英文"、"不支持翻译"、"必须用特定浏览器"等限制。

点击空白处退出提示



立项原因:观看外语直播、视频会议、在线课程时,非母语者无法实时理解内容。现成的字幕方案要么收费、要么延迟大、要么不支持系统音频。
业务背景:跨境直播、YouTube/Twitch 生肉内容、Zoom/Teams 国际会议三大场景都有强需求。市面上同类工具(如 OBS 字幕插件、Google Live Caption)普遍存在"英文输出英文"、"不支持翻译"、"必须用特定浏览器"等限制。
系统音频捕获:通过windows wasapi loopback抓取系统播放的所有声音,不依赖任何第三方音频驱动
语音活动检测:基于能量阈值自动切分语音段,静音自动短句,支持0.8-5s可调配音长度
语音转文字:faster-whisper tiny 模型本地推理, CPU int8量化,离线可用
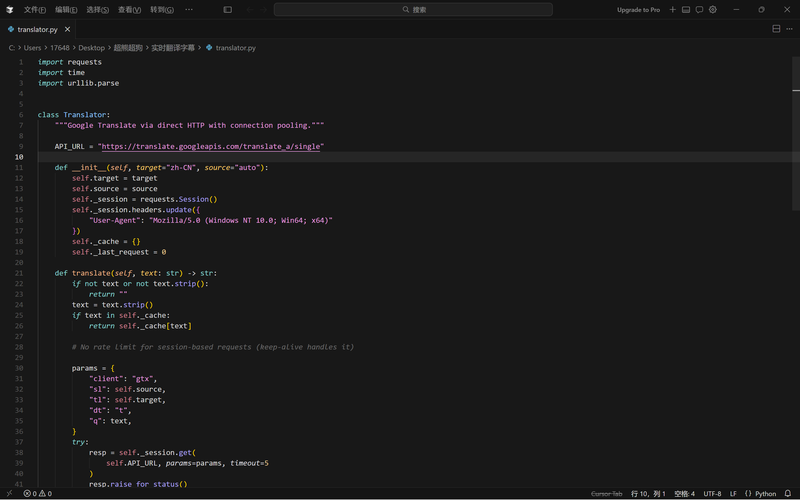
文本翻译:Google Translate API实时翻译,带 500条 LRU缓存避免重复请求
悬浮字幕窗:Tkinter 置顶无边框窗口,半透明背景,旧字幕渐暗消失,支持拖拽
技术栈:Python 3.10 + ctypes (WASAPI COM) + faster-whisper + tkinter + requests
架构:
系统音频 → WASAPI Loopback (ctypes) → 音频队列
↓
VAD 能量检测 + 语音切分
↓
STT 工作线程 (faster-whisper)
↓
翻译工作线程 (Google Translate)
↓
UI 主线程 (tkinter 悬浮窗)
亮点:
- 零第三方音频库:7 万行 audio_capture.py 全用 ctypes 手写 COM 接口调用,vtable 偏移手动计算,不依赖 PortAudio/SoundDevice/PyAudio
- 自适应格式:自动读取设备原生采样率和声道数,按需重采样到 Whisper 的 16kHz,立体声自动合并为单声道
- 多线程流水线:音频采集在主线程,STT 和翻译各占独立线程,有界队列 + 最旧丢弃策略防止内存堆积
- 实时性调优:40ms 主循环、0.6s 静音断句、最长 5s 强制切分,端到端延迟控制在 2-4 秒

评论