


很多中小企业在处理日常业务数据时,面临数据格式不统一、数据质量差、手动转换效率低的问题。业务部门产生的Excel报表、CSV导出文件、数据库记录等存在大量重复、缺失和异常数据,直接影响了后续分析和决策的准确性。本系统旨在为企业提供一个自动化的数据清洗和ETL处理方案,帮助业务人员快速完成数据预处理工作。

点击空白处退出提示



很多中小企业在处理日常业务数据时,面临数据格式不统一、数据质量差、手动转换效率低的问题。业务部门产生的Excel报表、CSV导出文件、数据库记录等存在大量重复、缺失和异常数据,直接影响了后续分析和决策的准确性。本系统旨在为企业提供一个自动化的数据清洗和ETL处理方案,帮助业务人员快速完成数据预处理工作。
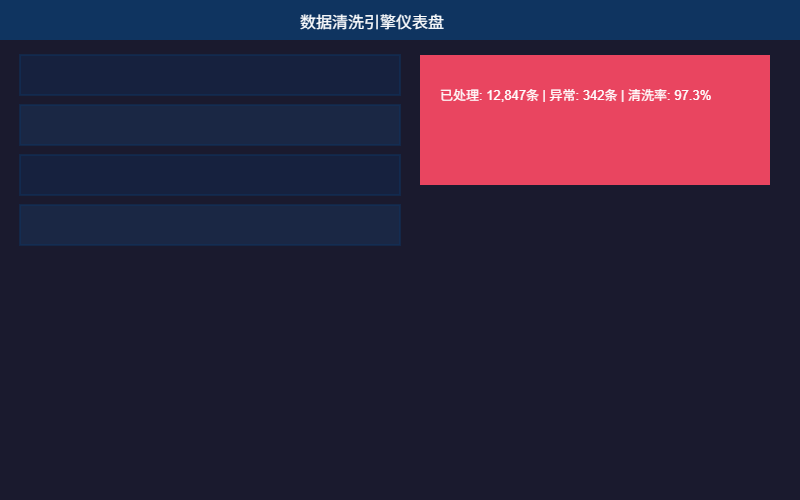
系统核心功能包括五个模块:1)数据源接入模块,支持Excel、CSV、JSON、XML等多种格式的数据导入,同时支持MySQL、PostgreSQL数据库直连;2)数据清洗模块,提供去重、空值填充、异常值检测与修正、格式标准化等功能;3)数据转换模块,支持字段映射、数据类型转换、正则提取、条件过滤、拆分合并等操作;4)ETL流程调度模块,支持可视化配置数据管道,可设置定时任务实现自动化处理;5)数据导出模块,支持清洗后的数据输出为Excel、CSV、JSON等格式。系统还提供了数据质量报告功能,自动生成清洗前后的数据对比统计。
我独立负责该项目的整体架构设计与全流程开发。后端采用Python语言,使用Flask框架构建RESTful API服务,Pandas库实现核心的数据清洗和转换逻辑,SQLAlchemy作为ORM层对接多数据库。数据处理流程使用管道架构模式设计,每个清洗节点可独立配置和组合复用。项目亮点是实现了可配置的规则引擎,用户只需编写简单的YAML配置文件即可定义复杂的数据清洗规则,无需修改代码。难点在于处理大规模数据时的内存优化,通过流式处理和分块计算的方式解决了大数据量的性能瓶颈。
评论