


本项目立项是为了解决公开网页资料整理效率低、手动复制信息耗时、竞品页面和服务目录难以批量归档的问题。适用于公开网站信息
采集、竞品分析、价格整理、联系方式线索提取、企业官网服务页整理等场景,帮助用户在合法公开页面范围内快速完成数据初筛和结
构化导出。

点击空白处退出提示



本项目立项是为了解决公开网页资料整理效率低、手动复制信息耗时、竞品页面和服务目录难以批量归档的问题。适用于公开网站信息
采集、竞品分析、价格整理、联系方式线索提取、企业官网服务页整理等场景,帮助用户在合法公开页面范围内快速完成数据初筛和结
构化导出。
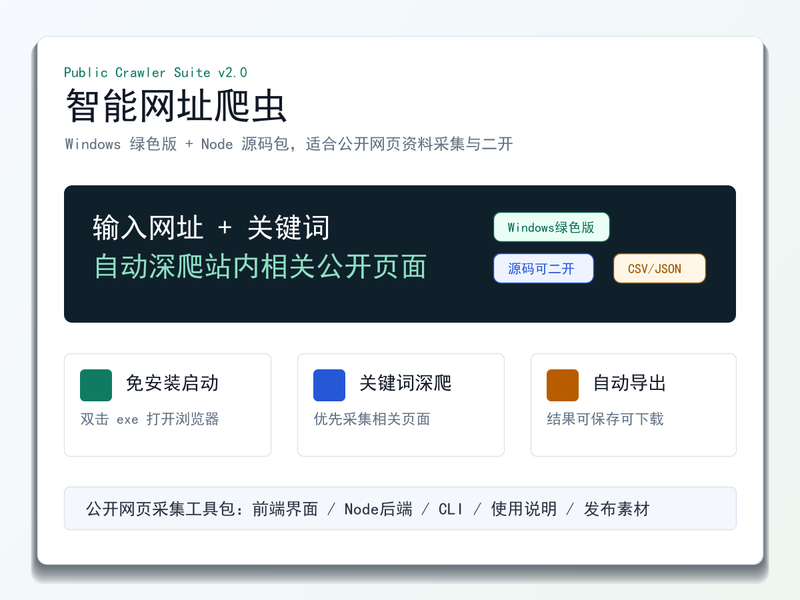
项目包含关键词智能采集、站内深度爬取、动态、可视化 Web 操作界面、Node.js 后端采集服务、CLI 命令行批处理、历史任务管理、
sitemap 导入、标题关键词匹配、域名去重、排除域名、线程和延迟控制等模块。系统可自动提取网页标题、描述、正文摘要、H1/H2/
H3、价格、邮箱、电话、图片、链接、表单、表格和 JSON-LD 结构化数据,并支持 CSV、JSON 和 result 文本结果导出。
我负责项目需求整理、采集流程设计、前后端功能实现、任务状态管理、导出功能、Windows 绿色版启动器适配、使用说明和交付包整
理。项目使用 Node.js 实现后端服务和采集逻辑,前端采用原生 HTML/CSS/JavaScript 构建操作页面,支持静态抓取和可选
Playwright 动态渲染。实现亮点包括关键词驱动的站内链接发现、域名维度去重、端口自动切换、实时日志、暂停继续停止控制,以
及无需数据库的轻量化本地部署。



评论