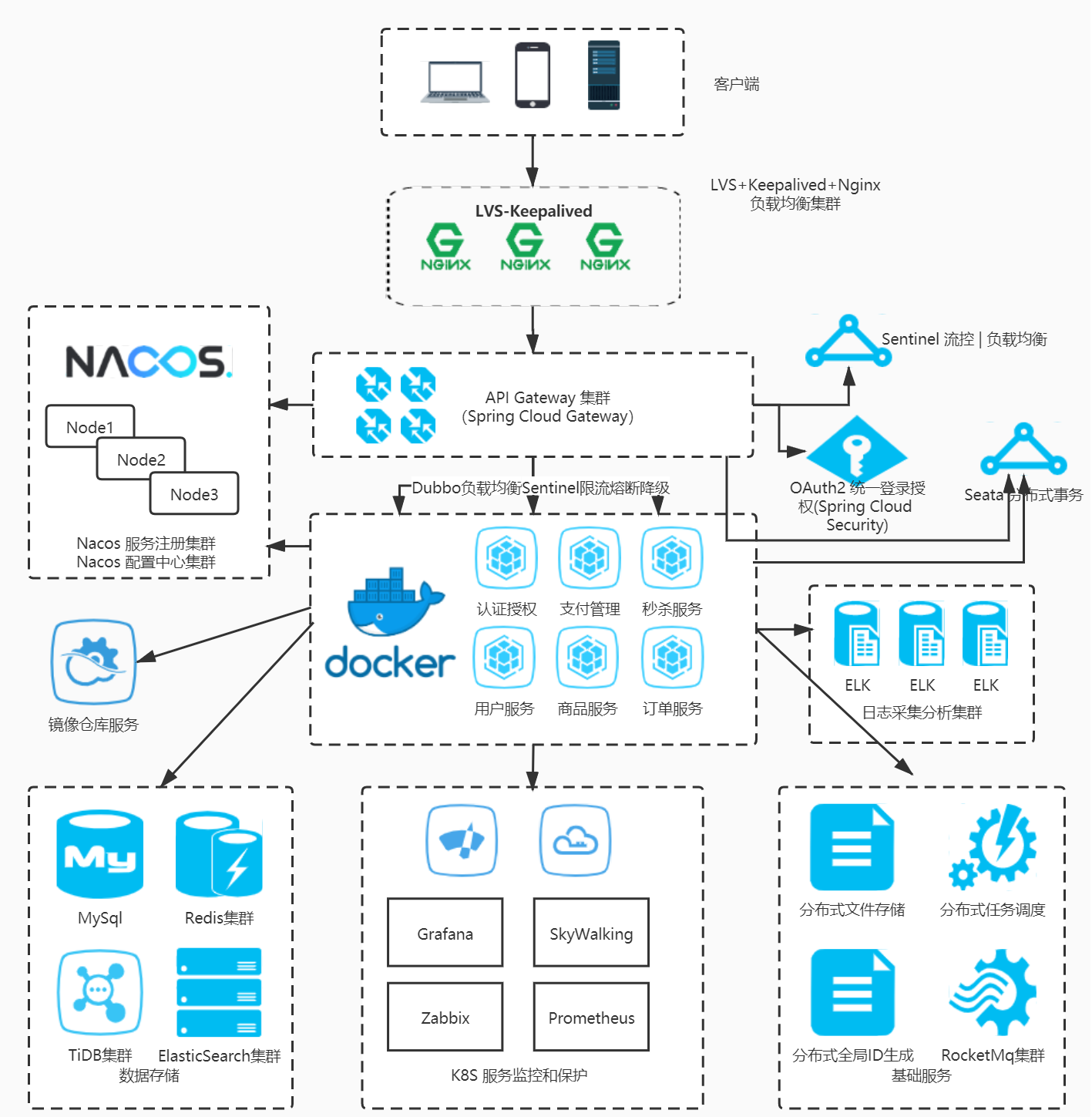
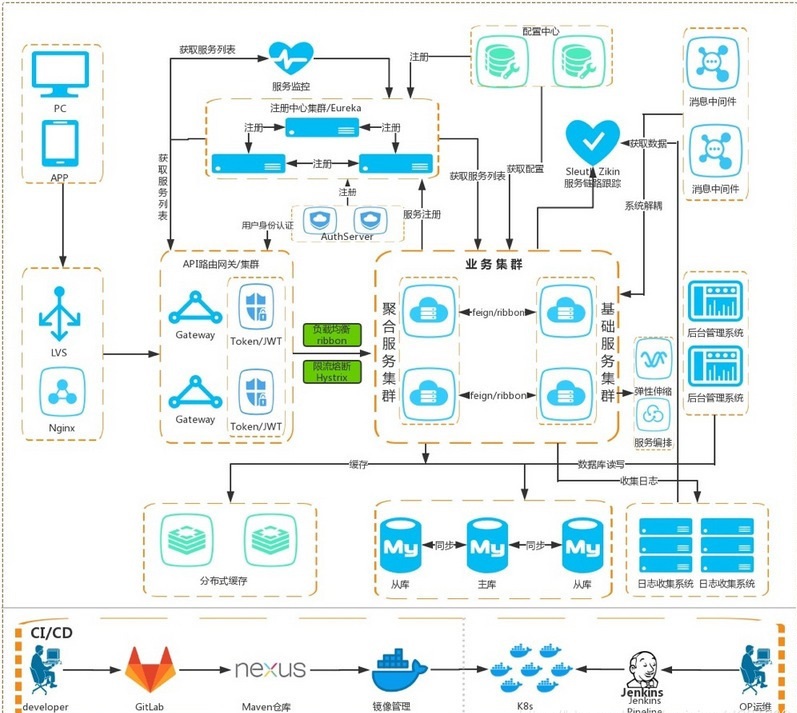
项目职责:
1.完成BMCTruesight监控产品的前期需求调研,架构设计,安装部署,监控配置配置,性能调优等工作
3.完成BMCTruesight监控产品与统一展现大屏的集成
4.通过SNMPtrap,Msend等完成BMCbppm监控产品与其他第三方监控产品的集成(Geneeinfo,安全网关)
6.完成客户生产环境中巡检需要的特定监控
7.完成项目中安装配置,维护手册的编写交付
8.完成客户的培训
9.完成监控报表的设计及配置
项目收益:
通过搭建智能监控运维平台,使得客户由人工对服务器,机房的巡检工作变成由机器自动监控,实时预警,大大提高了服务器运维效率及安全性,通过不同的告警通知机制(邮件,短信)将客户从口头,电话沟通处理事件升级为统一规范的处理流程,避免了人为造成的遗漏等问题,提升了客户IT管理的安全及规范。