首页
程序员
产品
招聘用人
云端工作
自由工作、远程工作
项目研发
需求梳理
规划落地您的想法
整包开发
一站式软件开发
云服务
UniSMS
合一短信 聚合API短信平台
技术
发布需求
开发者入驻
APP
登录
/
注册
全部
动态
开源项目
源文件源码
产品系统
Java
Python
C/C++
PHP
C#
TypeScript
Go
Swift
更多
opm-server-mirror
开源项目
代码更新 2009-11-25: 加入反爬虫功能。直接Web访问服务器将跳转到Google。 使用方法 下载index.zip 解压index.zip得到index.php 将index.php...
92
0
Java
网络爬虫
gcrawler 爬虫框架
开源项目
一个基于gevent的爬虫框架,最初的版本在一定程度上模仿了scrapy。
76
0
Python
网络爬虫
用ruby写的采集程序
开源项目
作为一个入门级的程序员,用ruby写的一个小脚本,可以采集某人才网的人才数据,写的不好。头一次发布,希望大大们批评指正。 采集某网站的人才数据,保存到csv文件中,同时导入数据库
65
0
Ruby
网络爬虫
Spiderman Java网络蜘蛛/网络爬虫
开源项目
Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,...
62
0
Java
网络爬虫
Common Crawl InputFormat 配送实现
开源项目
commoncrawl 源码库是用于 Hadoop 的自定义 InputFormat 配送实现。 Common Crawl 提供一个示例程序 BasicArcFileReaderSample.j...
95
0
Java
网络爬虫
易得网络数据采集系统
开源项目
本系统采用主流编程语言php和mysql数据库,您可以通过自定义采集规则,或者到我的网站下载共享的规则,针对网站或者网站群,采集您所需的数据,您也可以向所有人共享您的采集规则哦。通过数据浏览和编...
89
0
PHP
网络爬虫
MetaSeeker 网页抓取/信息提取软件
开源项目
爬虫软件MetaSeeker,现已全面升级为GooSeeker。 新版本已经发布,在线版免费下载和使用,源代码可阅读。自推出以来,深受喜爱,主要应用领域: 垂直搜索(Vertical Searc...
110
0
网络爬虫
QuickRecon 信息收集工具
开源项目
QuickRecon是一个简单的信息收集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats寻找人际关系等。QuickRec...
72
0
Python
网络爬虫
Ex-Crawler 网页爬虫
开源项目
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部分,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库存储网页信息。
91
0
Java
网络爬虫
PlayFish 网页抓取工具
开源项目
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具 应用开源jar包包括httpclient(内容...
89
0
Java
网络爬虫
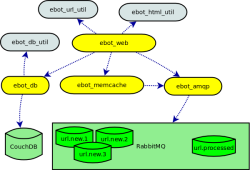
Ebot 分布式网页爬虫
开源项目
Ebot 是一个用 ErLang 语言开发的可伸缩的分布式网页爬虫,URLs 被保存在数据库中可通过 RESTful 的 HTTP 请求来查询。
63
0
ErLang
网络爬虫
jcrawl web爬虫
开源项目
jcrawl是一款小巧性能优良的的web爬虫,它可以从网页抓取各种类型的文件,基于用户定义的符号,比如email,qq.
64
0
Java
网络爬虫
hispider 网页爬虫框架
开源项目
HiSpider is a fast and high performance spider with high speed 严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能...
75
0
C/C++
网络爬虫
BlueLeech 网页搜索爬虫
开源项目
BlueLeech是一个开源程序,它从指定的URL开始,搜索所有可用的链接,以及链接之上的链接。它在搜索的同时可以下载遇到的链接所指向的所有的或预定义的范围的内容。
81
0
Java
网络爬虫
JobHunter 招聘信息爬虫
开源项目
JobHunter旨在自动地从一些大型站点来获取招聘信息,如chinahr,51job,zhaopin等等。JobHunter 搜索每个工作项目的邮件地址,自动地向这一邮件地址发送申请文本。
59
0
Java
网络爬虫
Methanol 网页爬虫
开源项目
Methanol 是一个模块化的可定制的网页爬虫软件,主要的优点是速度快。
65
0
C/C++
网络爬虫
JSpider Java网页爬虫
开源项目
JSpider 是一个用 Java 实现的 WebSpider,JSpider 的执行格式如下: jspider [URL] [ConfigName] URL 一定要加上协议名称,如:http:...
75
0
Java
网络爬虫
urlwatch URL监控脚本
开源项目
urlwatch 是一个用来监控指定的URL地址的 Python 脚本,一旦指定的 URL 内容有变化时候将通过邮件方式通知到。 基本功能 配置简单,通过文本文件来指定URL,一行一个URL地址...
94
0
Python
网络爬虫
Snoopy 网站内容采集器
开源项目
Snoopy 是一个强大的网站内容采集器(爬虫)。提供获取网页内容,提交表单等功能。
79
0
PHP
网络爬虫
Spidr
开源项目
Spidr 是一个Ruby 的网页爬虫库,可以将整个网站、多个网站、某个链接完全抓取到本地。 安装方法:sudo gem install spidr 代码示例: Spidr.start_at('...
67
0
Ruby
网络爬虫
当前共162084个项目
...
2500
2501
2502
2503
2504
2505
2506
2507
2508
2509
2510
...
登录
登录后即可上传、下载作品
搜索
分类
Perl
微信小程序
金融
Dart
Atom 插件
服务框架/平台
文档管理
Delphi/Pascal
Scala
ERP
×
寻找源码
源码描述
联系方式
提交
重点城市程序员兼职推荐
北京程序员兼职
上海程序员兼职
深圳程序员兼职
杭州程序员兼职
广州程序员兼职
成都程序员兼职
南京程序员兼职
武汉程序员兼职
西安程序员兼职
重庆程序员兼职
郑州程序员兼职
长沙程序员兼职
苏州程序员兼职
合肥程序员兼职
厦门程序员兼职
济南 程序员兼职
青岛程序员兼职
天津程序员兼职
大连程序员兼职
福州程序员兼职
石家庄程序员兼职
沈阳程序员兼职
太原程序员兼职
无锡程序员兼职
南昌程序员兼职
哈尔滨程序员兼职
南宁程序员兼职
珠海程序员兼职
宁波程序员兼职
昆明程序员兼职
东莞程序员兼职
贵阳程序员兼职
美国程序员兼职
长春程序员兼职
温州程序员兼职
佛山程序员兼职
常州程序员兼职
呼和浩特程序员兼职
兰州程序员兼职
乌鲁木齐程序员兼职
中山程序员兼职
海口程序员兼职
洛阳程序员兼职
更多
重点岗位程序员兼职推荐
C++兼职
Rust兼职
小程序兼职
cocos2d-x兼职
Unity3D兼职
DBA兼职
运维兼职
测试兼职
移动其他兼职
Go兼职
UE设计师兼职
全栈兼职
技术创始人兼职
CTO兼职
项目经理兼职
产品经理兼职
原画师兼职
UI设计师兼职
前端兼职
iOS兼职
Android兼职
Node.js兼职
Ruby兼职
架构师兼职
Python兼职
C#兼职
C兼职
PHP兼职
Java兼职
鸿蒙兼职
区块链兼职
人工智能兼职
硬件开发兼职
更多
您好 👋
我们能提供什么帮助?
向我们发送消息
常见问题、使用帮助、人工咨询等
智能搜索
手机访问
使用微信扫一扫