


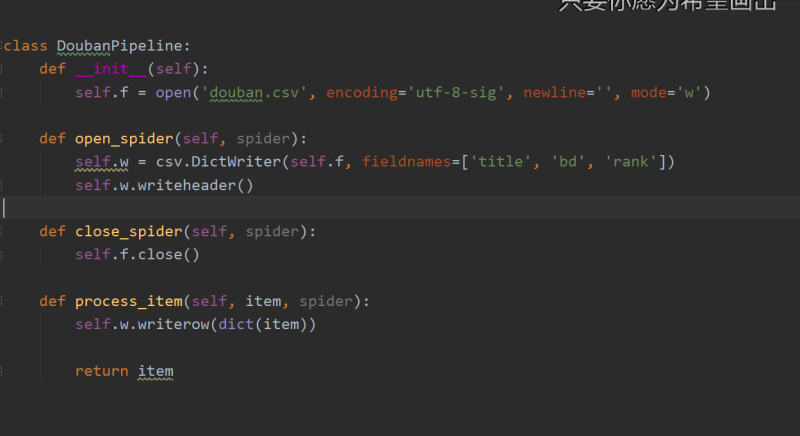
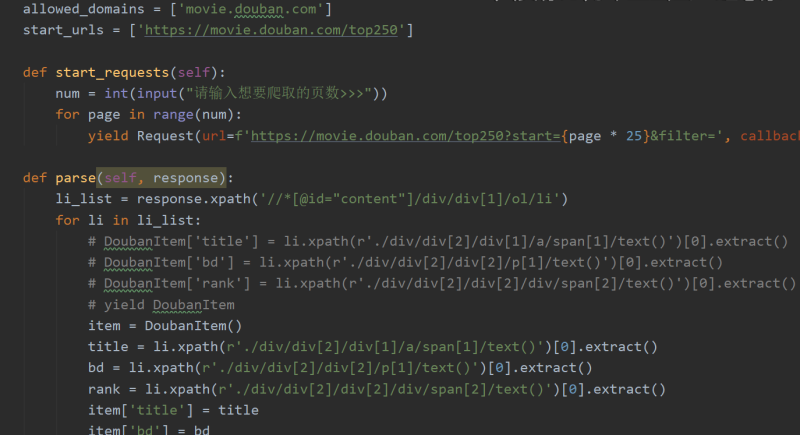
在进行豆瓣电影爬取这个项目中采用了scrapy框架进行爬取,首先在start_requests内对url进行重写再yield Requsets在parse中通过xpath对返回的网页数据进行解析和数据选择,最后在pipelines中实现持久化存储。

点击空白处退出提示



在进行豆瓣电影爬取这个项目中采用了scrapy框架进行爬取,首先在start_requests内对url进行重写再yield Requsets在parse中通过xpath对返回的网页数据进行解析和数据选择,最后在pipelines中实现持久化存储。
评论