


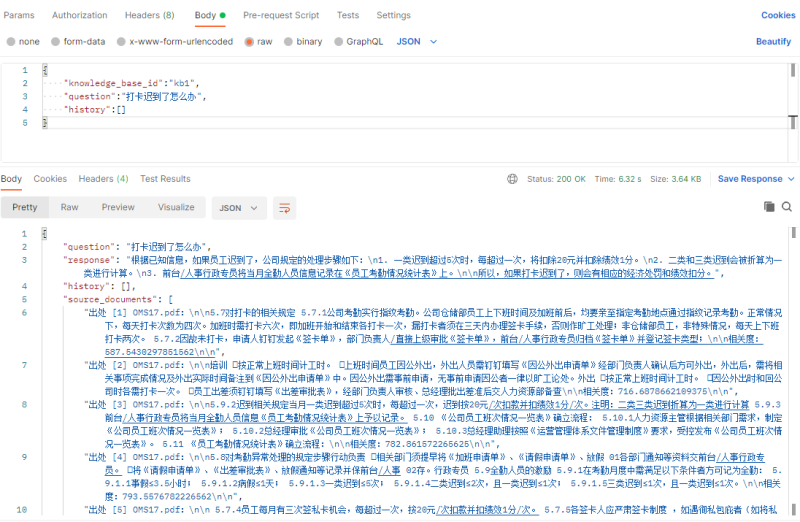
项目主要包括从文件系统拉取拉取相关的文件数据,然后对各种格式的文档使用langchain进行处理转化成doc,然后使用开源的embedding或gpt的embedding模型进行编码,最后根据用户提出的问题,先使用相似度检索检索出相关的文档,再使用chatgpt根据相关的文档进行答复;项目独立完成,难点在于要考虑文件系统文件的增加,删除和更新,还有避免等待焦虑的流式响应

点击空白处退出提示



行业分类
人工智能
项目主要包括从文件系统拉取拉取相关的文件数据,然后对各种格式的文档使用langchain进行处理转化成doc,然后使用开源的embedding或gpt的embedding模型进行编码,最后根据用户提出的问题,先使用相似度检索检索出相关的文档,再使用chatgpt根据相关的文档进行答复;项目独立完成,难点在于要考虑文件系统文件的增加,删除和更新,还有避免等待焦虑的流式响应
评论