





1. 分2个模块
(1)长文本分类,包括适用法律、转让、赔偿、终止权利、权限、信息安全、委托和担保等类别
(2)命名实体识别,包括乙方、主管、参与方等
实现了合同PDF文档自动化抽取关键信息到数据库,便于文档的管理、查询、使用
2. 我负责算法部分:
(1)使用OCR对PDF文档解析
(2)使用NER抽取实体公司名,与公司名词表进行相似度计算,匹配最相似实体
(3)使用BERT模型finetune,得到适用于该场景的分类模型,对文本进行分类,找到所属标签
(4)将抽取到的信息存入数据库
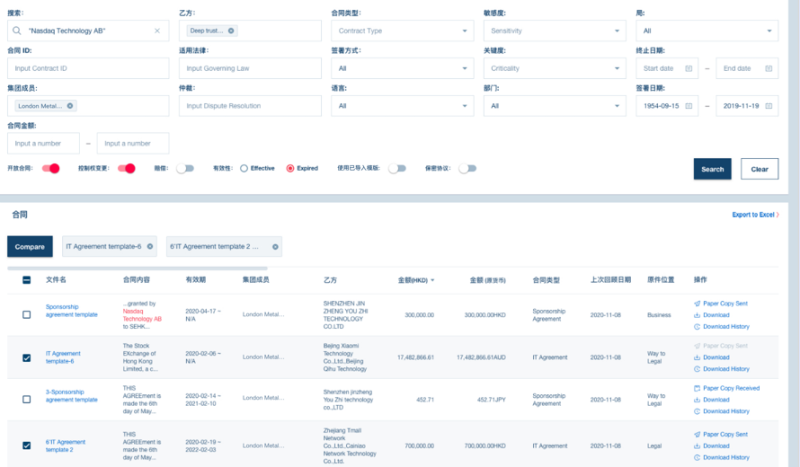
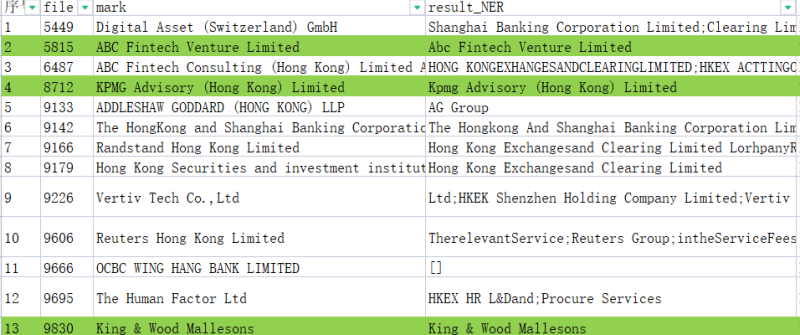

点击空白处退出提示
评论