


客户要求编写自动化程序,从指定网站上爬取债券的各种信息,并且自动下载文件整理到指定的目录中,还需要把最终的结果整合到excel表格里。

点击空白处退出提示



客户要求编写自动化程序,从指定网站上爬取债券的各种信息,并且自动下载文件整理到指定的目录中,还需要把最终的结果整合到excel表格里。
项目为Python编写的爬虫程序,根据客户给定的两个网站内容进行编写
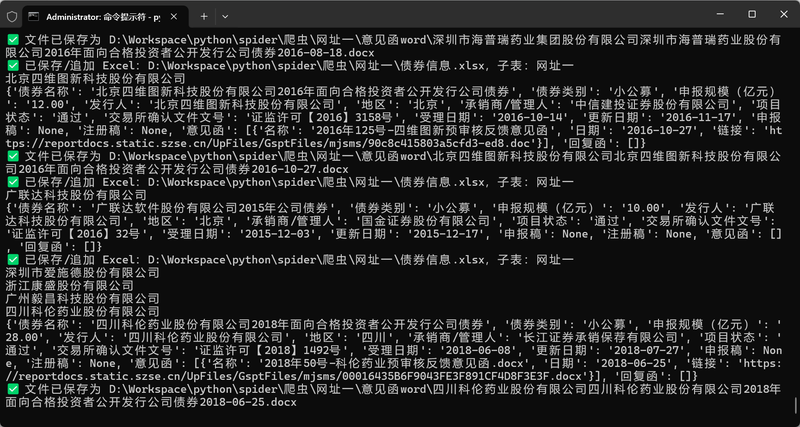
1.请求网站的api接口,传入指定的参数,解析返回的json数据
2.处理json数据,提取关键信息和文件下载链接
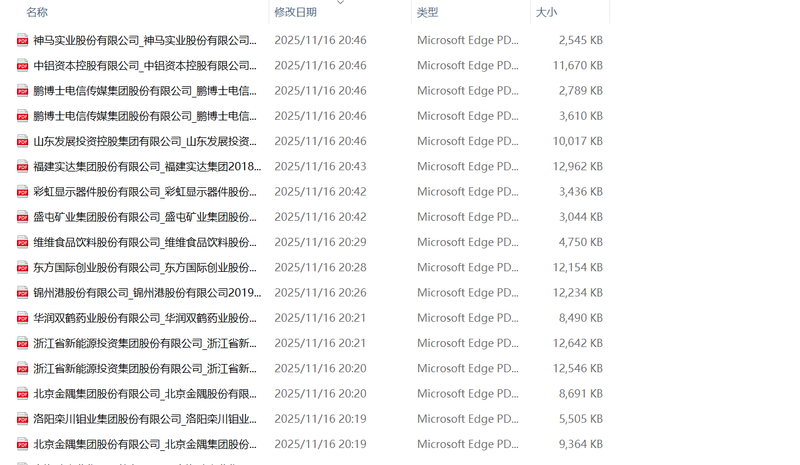
3.下载文件,并且根据文件的二进制内容判断文件的格式是zip、doc、docx还是pdf,然后进行相应的处理,如:zip解压后重命名,其它文件则是重命名后读取内容
4.把文件和数据整合到一个表格中
另一部分的代码是针对客户给出的第二个网站,需要使用selenium模拟浏览器进行爬取
1.从excel中读取客户给定的数据
2.通过xpath定位网页元素,模拟点击,控制网页内容
3.提取出网页上的关键信息,下载文件并整合数据进入表格
项目使用了Python、xpath、javascript、selenium这样的爬虫技术,我通过对这些技术的组合完成了客户的需求,给客户交付了完整的代码、运行完成后的结果

评论