


旧队列资源系统基于 Python2 遗留架构,存在严重的技术债务:
1. 一致性缺失:队列资源“潮汐”功能缺乏事务控制,异常中断导致平台数据与 Hadoop 数据不一致,引发资源错乱。
2. 架构臃肿难维护:过度依赖 MongoDB/Kafka/Spark 等冗余组件,且权限逻辑硬编码,与当前 Java 技术栈脱节。
3. 性能与策略瓶颈:潮汐策略僵化导致资源利用率低,且因数据模型缺陷造成核心页面响应延迟高达数十秒,严重制约运维效率。

点击空白处退出提示



旧队列资源系统基于 Python2 遗留架构,存在严重的技术债务:
1. 一致性缺失:队列资源“潮汐”功能缺乏事务控制,异常中断导致平台数据与 Hadoop 数据不一致,引发资源错乱。
2. 架构臃肿难维护:过度依赖 MongoDB/Kafka/Spark 等冗余组件,且权限逻辑硬编码,与当前 Java 技术栈脱节。
3. 性能与策略瓶颈:潮汐策略僵化导致资源利用率低,且因数据模型缺陷造成核心页面响应延迟高达数十秒,严重制约运维效率。
新系统包括但不限于以下核心功能
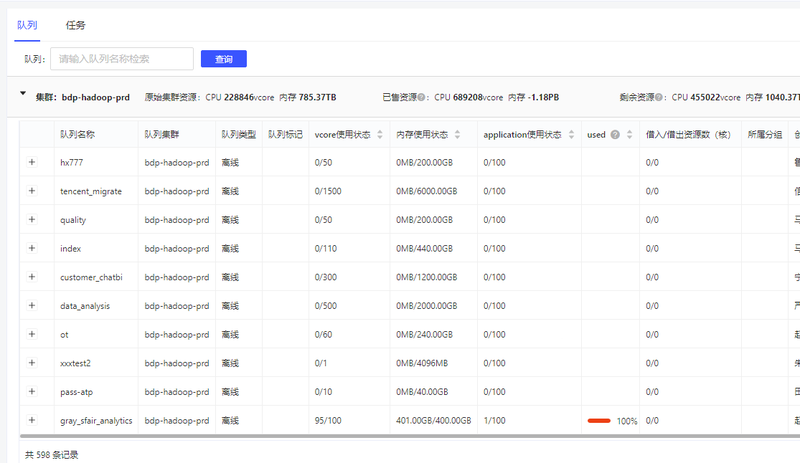
1.队列资源管理
2.队列潮汐
3.队列分组
4.队列使用权限
5.队列任务
6.队列灰度策略
7.队列审计历史
8.队列临时策略
首先,为了彻底解决旧系统的痛点,我执行了三个关键动作:
第一,建立原子性与串行化机制。我重写了核心业务逻辑,强制要求潮汐资源的借出与归还必须满足事务和原子性,并配合后台操作的串行化,彻底消除队列数据错乱导致的‘滚雪球效应’。
第二,架构与性能优化。我利用 Spring AOP 和 MyBatis 插件重构了复杂的权限系统,同时移除了对 Kafka 和 Spark 的冗余依赖,改为直接采集 Yarn 接口数据并利用 MySQL 批量写入,将外部依赖组件从 3 个降为 0。
第三,提升资源利用率。我设计了一套时间重叠算法,解除了‘同一时间只能设置一个潮汐任务’的限制,使队列资源利用率提升了 30%。
最终,这次重构实现了 0风险 上线,将半年度平均故障次数降为 0,大幅提升了系统的稳定性。我也为此输出了一项技术专利”
其次,系统稳定后我们面临了新的挑战:核心 S 级任务经常因资源竞争导致 SLA 延迟。
为了解决这个问题,我深入钻研了 Hadoop Yarn 的资源分配源码。基于源码分析,我否决了简单的‘加大资源’方案,而是设计了一套‘动态临时队列’方案。
具体做法是:当检测到 S 级任务延迟时,系统会自动根据任务历史的 Map/Reduce 数量计算所需 CPU 核数,为其动态创建一个独享资源的临时队列,将任务无缝迁移过去运行,任务结束后自动销毁队列。
这个方案有效解决了资源抢占问题,将核心任务的加速效果提升了 30% 到 50%。”
评论