


为满足企业对公开数据的采集与分析需求,解决人工收集效率低、数据格式不统一等问题,面向数据服务、电商及信息咨询行业提供定制化爬虫解决方案。

点击空白处退出提示



为满足企业对公开数据的采集与分析需求,解决人工收集效率低、数据格式不统一等问题,面向数据服务、电商及信息咨询行业提供定制化爬虫解决方案。
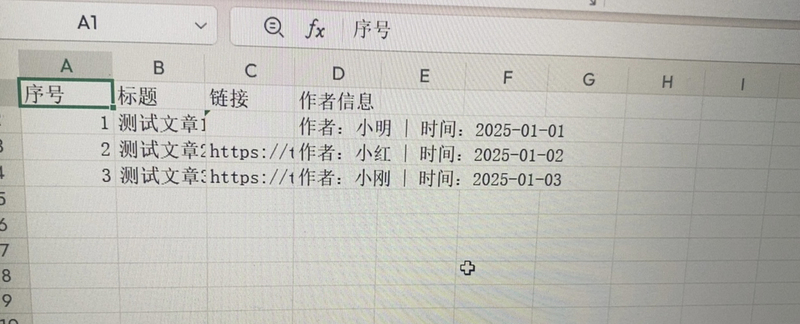
本项目基于Python开发,核心功能包括:1. 网页数据抓取,支持动态页面与常规反爬处理;2. 数据清洗与去重,可过滤无效信息;3. 结构化导出,支持Excel、CSV、JSON等多种格式输出;4. 定时采集与增量更新,保障数据时效性与完整性,高效满足企业数据分析需求。
本项目采用 Python 技术栈实现,核心技术选型如下:
1. 数据采集层:使用 Requests 发起 HTTP 请求,结合 Selenium 处理 JavaScript 动态渲染页面,针对常见反爬机制(如 IP 封禁、验证码、请求头校验),通过代理池轮换、UA 伪装、请求频率控制等方案进行规避。
2. 数据解析层:基于 XPath、BeautifulSoup 或 PyQuery 提取页面结构化数据,使用正则表达式清洗非目标内容。
3. 数据存储层:支持将清洗后的数据导出为 Excel、CSV、JSON 格式,或写入 SQLite/MySQL 数据库进行持久化存储。
4. 工程化优化:通过 Scrapy 框架实现爬虫任务的分布式调度与增量更新,搭配日志系统记录运行状态,保障脚本稳定性与可维护性,可根据业务需求快速定制采集规则。

评论