


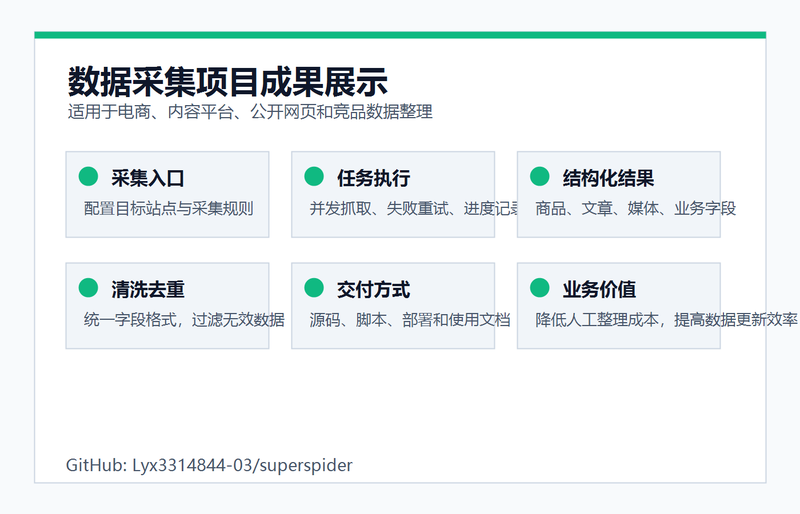
该项目面向电商、内容平台、公开网页数据采集和自动化运营场景,主要解决多站点数据抓取、网页动态渲染、反爬限制、结构化抽取和批量任务调度问题。适合用于商品信息采集、公开内容归档、竞品数据整理、业务报表数据来源建设等场景。

点击空白处退出提示



该项目面向电商、内容平台、公开网页数据采集和自动化运营场景,主要解决多站点数据抓取、网页动态渲染、反爬限制、结构化抽取和批量任务调度问题。适合用于商品信息采集、公开内容归档、竞品数据整理、业务报表数据来源建设等场景。
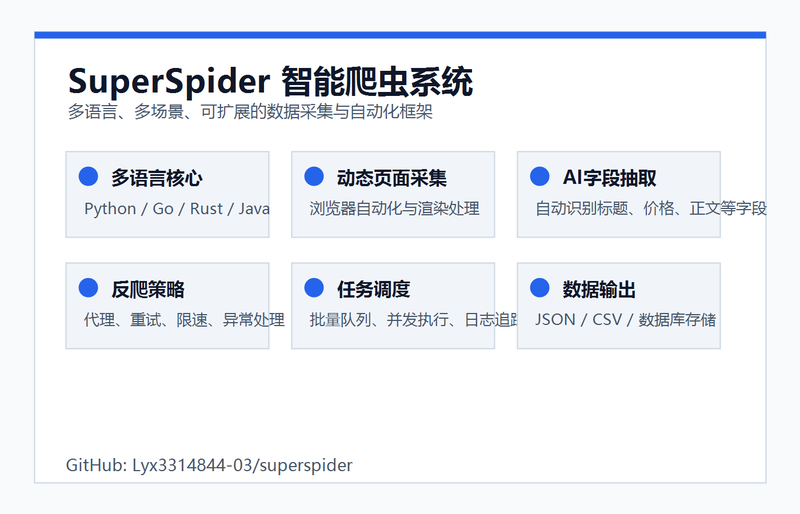
项目提供多语言爬虫实现与模块化采集能力,覆盖 Python、Go、Rust、Java 等技术栈。核心功能包括浏览器自动化采集、AI 辅助字段抽取、代理与反爬策略、分布式任务队列、媒体资源下载、电商公开数据采集、日志记录和结果持久化。通过统一的任务结构,可以快速扩展不同目标网站的采集逻辑,降低重复开发成本。
本人负责项目整体架构设计、爬虫模块实现、任务调度流程、数据抽取逻辑和多语言版本组织。实现中重点处理了动态页面渲染、请求重试、代理切换、结构化字段清洗、批量任务并发和可扩展模块划分。项目以 GitHub 开源仓库形式维护,便于客户查看源码、运行示例和评估开发能力。
评论