


面向复杂长文本/技术文档/结构化数据的自动化生成场景,解决单一AI模型生成质量不稳定、上下文漂移、字数失控等痛点。系统采用工业流水线模式,将"规划→生成→校验→缝合"分层解耦,适用于内容平台、技术文档生产、自动化报告生成等需要高可控性AI输出的业务场景。

点击空白处退出提示



面向复杂长文本/技术文档/结构化数据的自动化生成场景,解决单一AI模型生成质量不稳定、上下文漂移、字数失控等痛点。系统采用工业流水线模式,将"规划→生成→校验→缝合"分层解耦,适用于内容平台、技术文档生产、自动化报告生成等需要高可控性AI输出的业务场景。
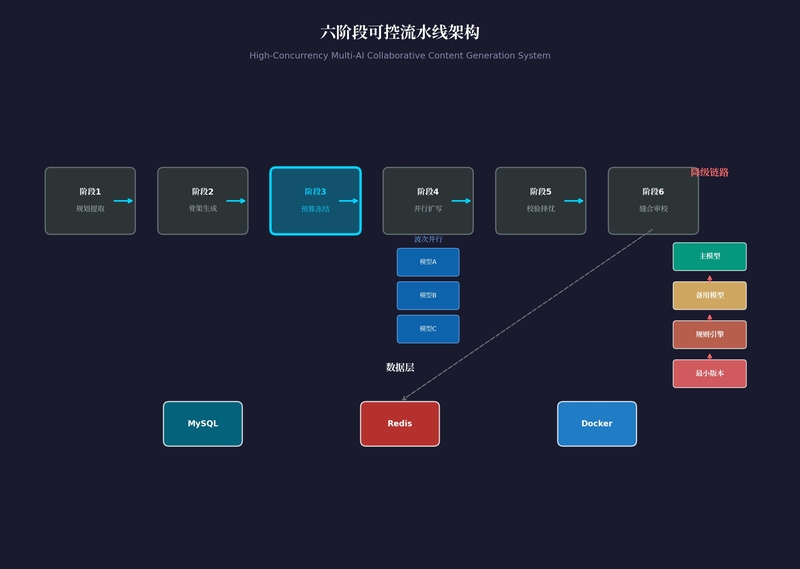
系统核心为六阶段可控流水线:
1.
规划提取:从结构化数据中提取确定性蓝图,零AI依赖
2.
骨架生成:生成标准化指令JSON,不生成正文,职责纯粹
3.
预算冻结:算法级字数强制对齐,执行freeze()后状态不可变
4.
并行扩写:多模型波次并行生成,动态波长(3/5/7段自适应),超时单段独立熔断
5.
校验择优:两层过滤(字数硬门槛+质量评分),通过段落写入缓存
6.
缝合审校:只允许插入过渡内容,严禁修改正文,符合冻结原则
附加功能:多模型降级链路(主模型→备用→规则引擎→最小版本)、熔断与自动恢复、预算会计分离、全链路哈希存证。
独立负责系统架构设计与后端开发。核心难点与解决:
状态冻结机制:设计StateBoard.deepFreeze(),阶段三后只读引用,防止高波动性AI生成篡改规划基线
波次并行引擎:波次内100%完成后提取真实摘要注入下一波次,平衡并发与上下文一致性
五级降级链路:任何单点故障不中断流程,主模型成功率低于60%自动熔断,独立线程池异步降级
并发安全:CopyOnWriteArrayList保障线程一致性,DegradationPolicy拒绝任务后提交独立fallbackExecutor
技术栈:Java 17、Spring Boot、JPA/Hibernate、MySQL、Redis、Docker、Gradle。
评论